The purpose of multiple regression is to predict a single variable from one or more independent variables. Multiple regression with many predictor variables is an extension of linear regression with two predictor variables. A linear transformation of the X variables is done so that the sum of squared deviations of the observed and predicted Y is a minimum. The computations are more complex, however, because the interrelationships among all the variables must be taken into account in the weights assigned to the variables. The interpretation of the results of a multiple regression analysis is also more complex for much the same reason.
The prediction of Y is accomplished by the following equation:
Y'i = b0 + b1X1i + b2X2i + ... + bkXki
The "b" values are called regression weights and are computed in a way that minimizes the sum of squared deviations
in the same manner as in simple linear regression. In this case there are K independent or predictor variables rather than two and K + 1 regression weights must be estimated, one for each of the K predictor variable and one for the constant (b0) term.
The data used to illustrate the inner workings of multiple regression will be generated from the "Example Student." The data are presented below:
| Subject | Age | Gender | Married | IncomeC | HealthC | ChildC | LifeSatC | SES | Smoke | Spirit | Finish | LifeSat7 | Income7 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 16 | 0 | 0 | 0 | 38 | 0 | 17 | 17 | 1 | 30 | 1 | 22 | 26 |
| 2 | 28 | 1 | 0 | 0 | 38 | 0 | 16 | 21 | 1 | 39 | 1 | 20 | 15 |
| 3 | 16 | 1 | 16 | 52 | 1 | 39 | 40 | 0 | 30 | 1 | 42 | 88 | |
| 4 | 23 | 1 | 0 | 6 | 51 | 0 | 22 | 31 | 0 | 60 | 1 | 48 | 73 |
| 5 | 18 | 0 | 1 | 7 | 52 | 0 | 25 | 38 | 0 | 32 | 0 | 14 | |
| 6 | 30 | 0 | 1 | 25 | 43 | 2 | 53 | 36 | 1 | 39 | 0 | 33 | 38 |
| 7 | 19 | 0 | 1 | 19 | 55 | 0 | 28 | 41 | 0 | 51 | 1 | 33 | 45 |
| 8 | 19 | 1 | 0 | 0 | 52 | 2 | 17 | 52 | 0 | 35 | 1 | 21 | 16 |
| 9 | 34 | 0 | 0 | 29 | 60 | 2 | 20 | 56 | 0 | 23 | 1 | 26 | 64 |
| 10 | 16 | 1 | 0 | 0 | 53 | 0 | 21 | 27 | 0 | 29 | 0 | 37 | 19 |
| 11 | 25 | 1 | 0 | 3 | 39 | 0 | 18 | 34 | 1 | 61 | 1 | 40 | 56 |
| 12 | 16 | 1 | 1 | 1 | 42 | 0 | 31 | 29 | 1 | 58 | 1 | 35 | 70 |
| 13 | 16 | 0 | 0 | 43 | 0 | 15 | 28 | 1 | 39 | 1 | 32 | 71 | |
| 14 | 16 | 0 | 1 | 18 | 54 | 1 | 34 | 38 | 0 | 40 | 0 | 37 | 44 |
| 15 | 16 | 1 | 0 | 0 | 52 | 0 | 20 | 38 | 0 | 27 | 1 | 35 | 25 |
| 16 | 32 | 1 | 1 | 26 | 54 | 1 | 39 | 37 | 0 | 30 | 47 | 38 | |
| 17 | 19 | 0 | 0 | 0 | 46 | 0 | 17 | 25 | 0 | 36 | 1 | 26 | 39 |
| 18 | 17 | 1 | 1 | 10 | 55 | 2 | 48 | 53 | 0 | 43 | 0 | 42 | 6 |
| 19 | 24 | 0 | 0 | 17 | 52 | 0 | 16 | 36 | 0 | 54 | 1 | 38 | 75 |
| 20 | 26 | 1 | 1 | 57 | 1 | 39 | 41 | 0 | 32 | 1 | 42 | 67 |
The major interest of this study is the prediction of life satisfaction seven years after college from the variables that can be measured while the student is in college. These data are available both as a text file and as an SPSS data file.
After doing a univariate analysis to check for outliers, the first step in analysis of data such as this is to explore the relationship borders. The minimum border of the relationships will be the bivariate correlations of all possible predictor variables with the dependent measures, LifeSat7 and Income7. The maximum border will be a linear regression model with all possible predictor variables in the regression model.
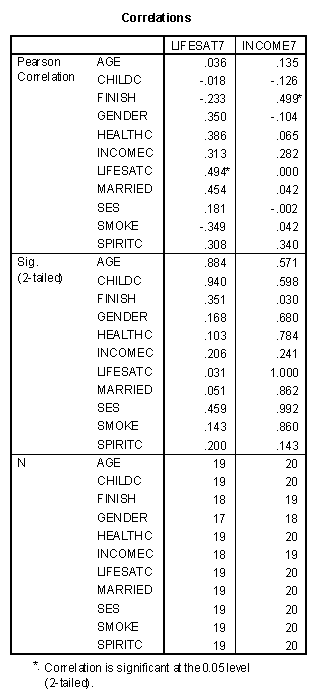
The correlation matrix is given below for all possible predictor variables and the two dependent measures, LifeSat7 and Income7.
The best and only significant ( =.05) predictor of life satisfaction seven years after college was life satisfaction in college with a correlation coefficient of .494. Other relatively high correlation coefficients included: Married (.454), Health in College (.386), Gender (.350 with females showing a generally higher level of life satisfaction), and Smoking (-.349 with Non-smokers showing a generally higher level of life satisfaction).
Income seven years after college was best predicted by knowing whether the student finished the college program or not (.499). Other variables that predicted income included the measure of spirituality (.340) and income in college (.282).
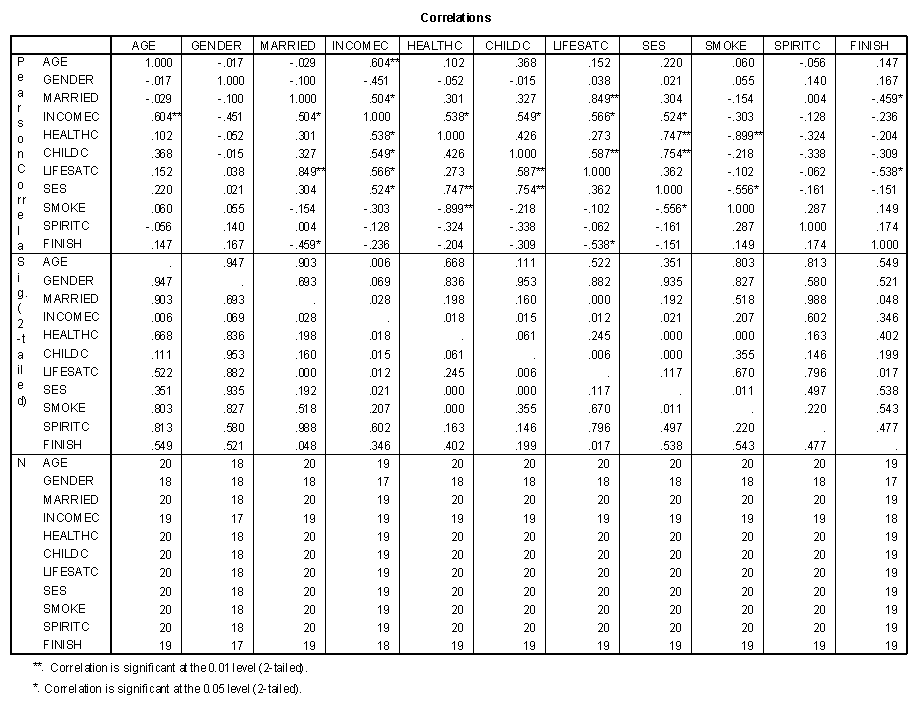
The matrix of correlations of all predictor variables is presented below.
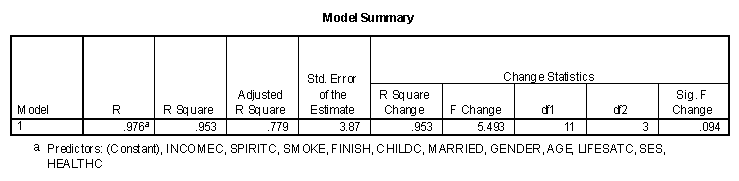
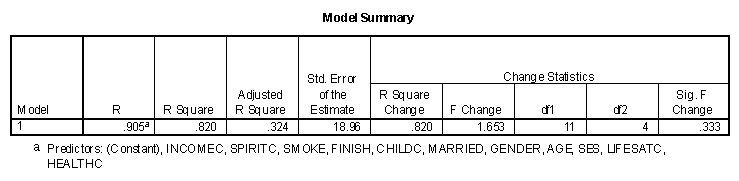
The other boundary in multiple regression is called the full model, or model with all possible predictor variables included. To construct the full model, all predictor variables are included in the first block and the "Method" remains on the default value of "Enter." The three tables of output for life satisfaction seven years after college are presented below.
Note that the unadjusted multiple R for this data is .976, but that the adjusted multiple R is .779. This rather large change is due to the fact that a relatively small number of observations are being predicted with a relatively large number of variables. the unadjusted value of R2 means that all subsets of predictor variables will have a value of multiple R that is smaller than .976. Note also that these variables in combination do not significantly (Sig. F Change = .094) predict life satisfaction seven years after college.
The middle table ANOVA doesn't provide much information in addition to the R2 change in the previous table. Note that the "Sig. F Change" in the preceding table is the same as the "Sig." value in the "ANOVA" table. This table was more useful in previous incarnation of multiple regression analysis (see Draper and Smith, 1981).
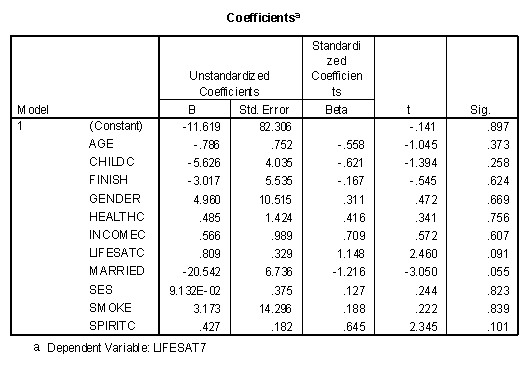
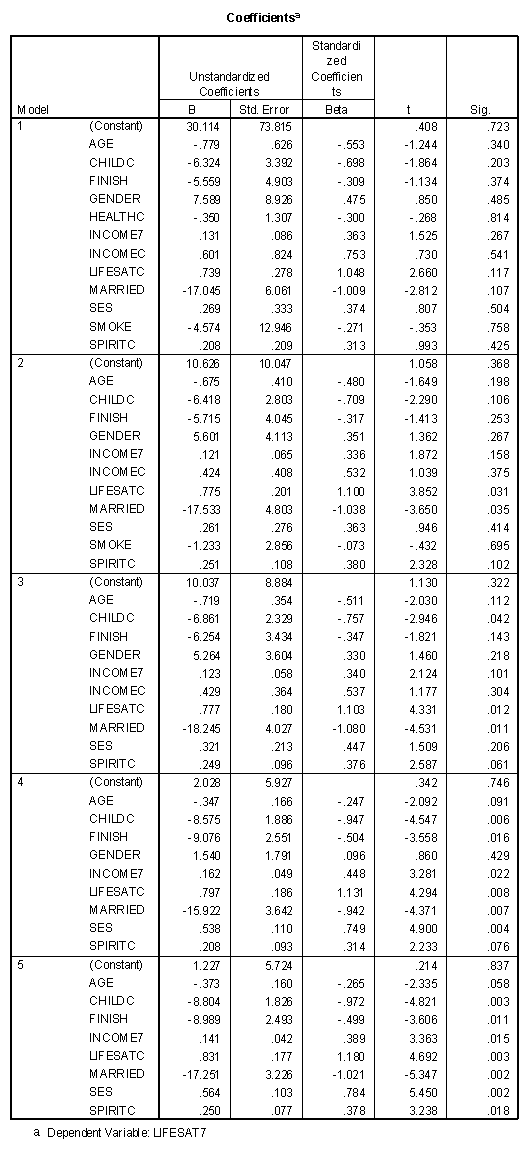
The full model is not statistically significant (F = 5.493, df = 11,3, sig.= .094), even though life satisfaction in college was statistically significant (p<.05) by itself. The value for this table had a total degrees of freedom of 14 because four observation had missing data and were not included in the analysis. The other degree of freedom corresponds to the intercept (constant) of the regression line. The method of handling missing data is called "listwise" because all data for a particular observation are not included if a single variable is missing.
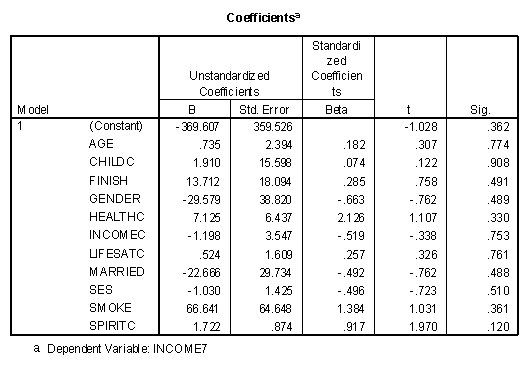
The "Sig." column on the "Coefficients" table presents the statistical significance of that variable given all the other variables have been entered into the model. Note that no variables are statistically significant in this table. The variable "Married" comes close (Sig. = .055), but close doesn't count in significance testing.
Previously it was found that the correlation between being married and life satisfaction seven years after college was relative high and positive (.454), meaning that individuals who were married in college were generally more satisfied with life seven years later. The regression weight for this same variable in the full model was negative (-20.542), meaning that over twenty points would be subtracted from an individual's predicted life satisfaction score seven years after college if they were married in college! Such are the nuances of multiple regression.
Partial output for the full model predicting the other dependent measure, income seven years after college, is presented below.
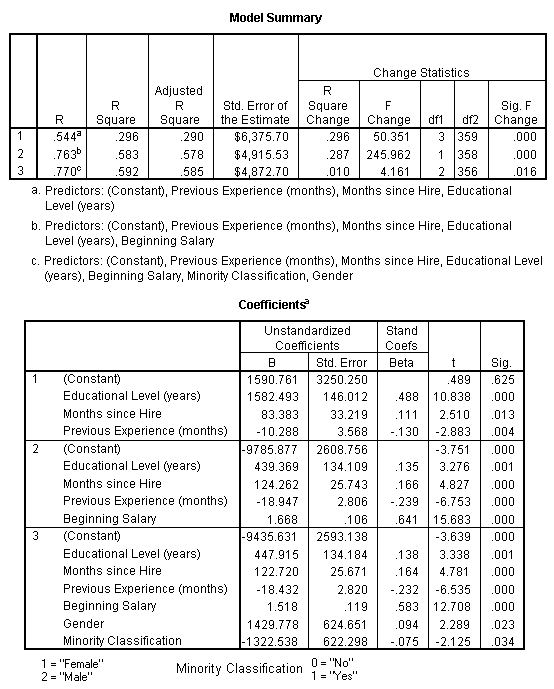
The results are similar to the prediction on life satisfaction, with an unadjusted multiple R of .905, giving an upper limit to the combined predictive power of all the predictor variables.
After the boundaries of the regression analysis have been established, the area between the extremes may be examined to get an idea of the interaction between the independent variables with respect to prediction. There are different schools of thought about how this should be accomplished. One school, hierarchical regression, argues that theory should drive the statistical model and that the decision of what and when terms enter the regression model should be determined by theoretical concerns. A second school of thought, stepwise regression, argues that the data can speak for themselves and allows the procedure to select predictor variables to enter the regression equation.
Hierarchical regression adds terms to the regression model in stages. At each stage, an additional term or terms are added to the model and the change in R2 is calculated. An hypothesis test is done to test whether the change in R2 is significantly different from zero.
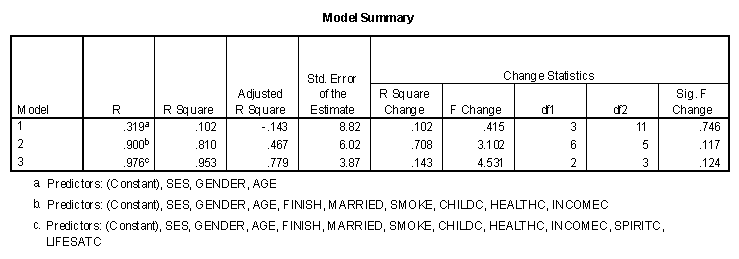
Using the example data, suppose a researcher wishes to examine the prediction of life satisfaction seven years after college in several stages. In the first stage, he/she enters demographic variables that the individual has little or no control over, age, gender, and socio-economic status of parents. In the second block variables are entered that the individual has at least some control, such as smoking, having children, being married, etc. The third block consists of the two attitudinal variables, life satisfaction and spirituality. This is accomplished in SPSS by entering the independent variables in blocks. Be sure the R2 change box is selected as a "Statistics" option.
The first table is a table of what variables were entered or removed at the different stages. The second table is summary of the results of the different models.
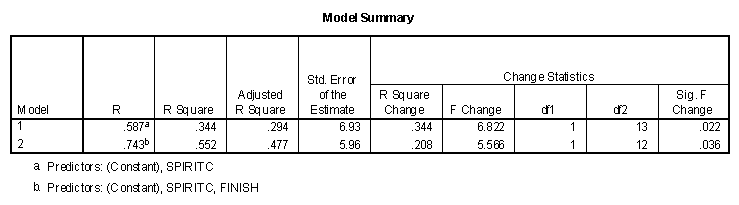
The largest change in R2 was from model 1 to model 2, with an R2 change of .708 from .102 to .810. This value was not significant, however, as were R2 changes associated with either of the other two models. Then final model has the same multiple R as the full model presented in an earlier section.
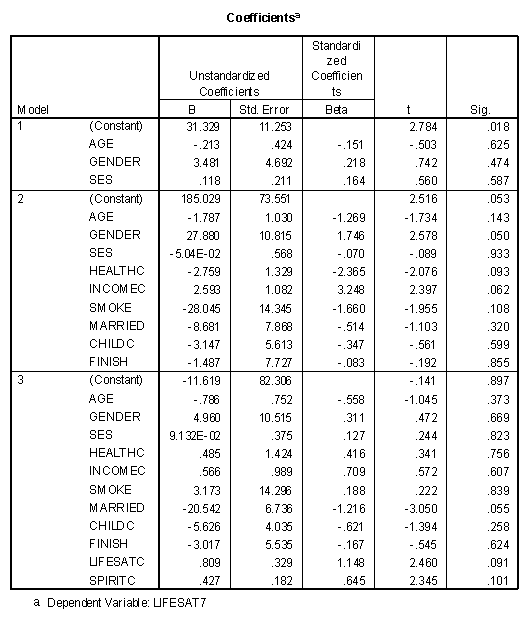
The third table presents the ANOVA significance table for the three models. The fourth table contains the regression weights and significance levels for each model. As before, the "Sig." column is an hypothesis test of the significance of that variable, given all the other variables at that stage have been entered into the model.
Note how the values of the regression weights and significance levels change as a function of when they have been entered into the model and what other variables are present.
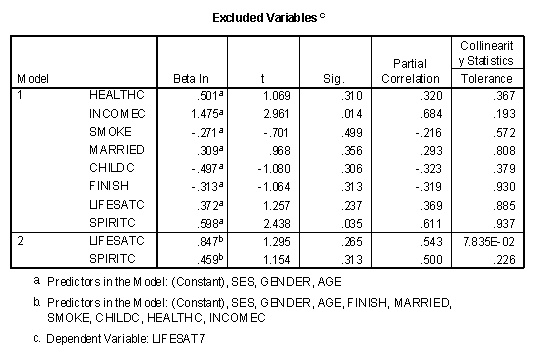
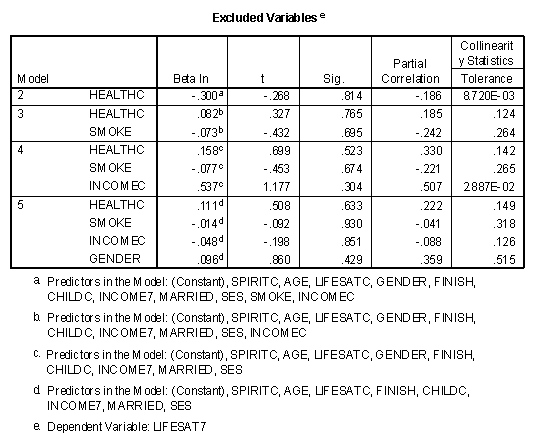
The fifth table presents information about variables not in the regression equation at any particular stage, called excluded variables.
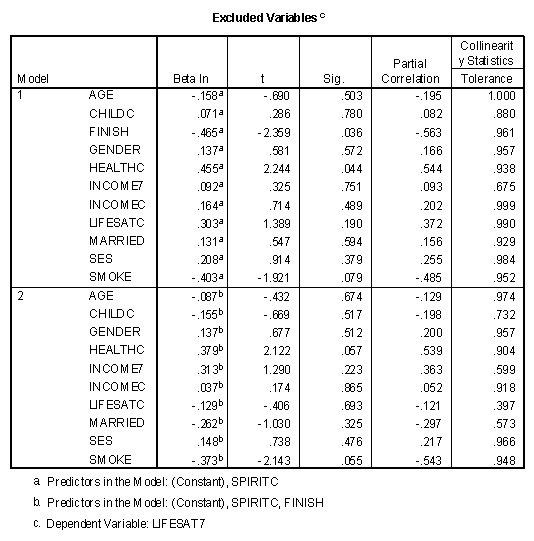
The value of "Beta In" is the size of the standardized regression weight if that variable had been entered into the model by itself in the next stage. The "Sig." column is the R2 change significance level that the variable would enter the regression equation. In this case, it can be seen that individually both INCOMEC and SPIRITC would significantly enter the regression model in the second stage. The "Partial Correlation" is the correlation between that variable and the residual of the previous model. The higher the partial correlation, the greater the change in R2 if that variable were entered into the equation by itself at the next stage.
As described in the help files of SPSS, the "Collinearity Statistics Tolerance" is "calculated as 1 minus R squared for an independent variable when it is predicted by the other independent variables already included in the analysis." This statistic may be interpreted as "A variable with very low tolerance contributes little information to a model, and can cause computational problems." (SPSS v. 10 help files.) In this case LIFESATC has a low Collinearity Statistics Tolerance (7.835E-02 or .07835) in model 2 and might cause problems if entered into the model at that point. Problems in collinearity were discussed in an earlier chapter in this text.
At any stage, rather than entering all the variables as a block, step-up regression enters the variables one at a time, the order of entry determined by the variable that causes the greatest R2 increase, given the variables already entered into the model. To do a step-up regression using SPSS, enter all the variables in the first block and select "Method" as "Forward."
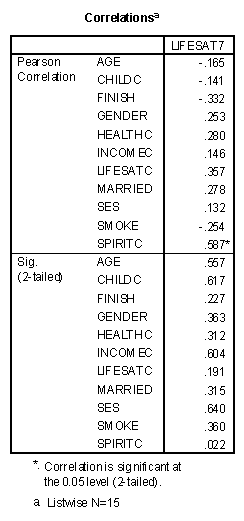
The results of the step-up regression can be better understood if the correlation coefficients are recomputed between life satisfaction seven years after college and all the predictor variables, using the "Listwise" option for missing data.
Note that the correlation coefficients have changed from the original table and that the highest correlation is with SPIRITC with a value of .587. The SPIRITC variable, then, would enter the step-up regression in the first step. The partial correlation of all the remaining variables and the residual of the first stage model would then be computed. The variable with the largest partial correlation would be entered into the regression at the next step, given that it was statistically significant. The criteria for entering variables into the regression model may be optionally adjusted.
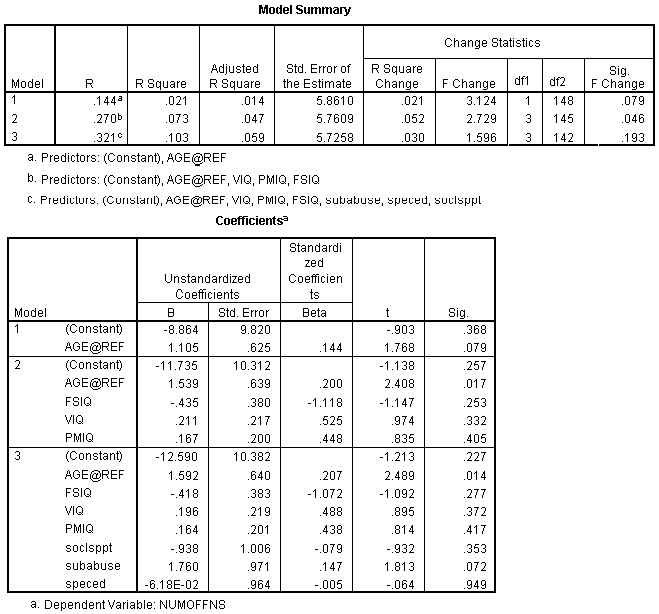
The "Model Summary" table shows that two variables, SPIRITC and FINISH, are entered into the prediction model with a multiple R of .743. The SPIRITC variable was entered first (it had the largest correlation with life satisfaction) and FINISH was entered next.
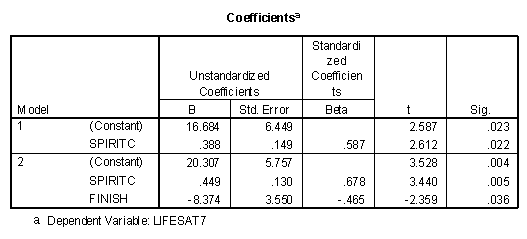
The "Coefficients" table is presented next.
The final table presents information about variables not in the regression equation.
At the conclusion of the first model, both FINISH and HEALTHC would significantly (p<.05) enter the regression equation at the next step. Since FINISH had a higher partial correlation (-.653) than HEALTHC (.544) it was entered into the equation at the next step. When FINISH was entered into the equation in model 2, HEALTHC would no longer significantly enter the regression model.
By starting with a full model and eliminating variables that do not significantly enter the regression equation, a partial model may be found. This can be accomplished in SPSS by selecting a "Method" of "Backward" in the linear regression procedure. As can be seen below, the results of this analysis differ greatly from the use of the Forward Method.
The Model Summary table is presented below.
As the table above illustrates, this method starts with the full model with an R2 of .978. The variable of HEALTC is eliminated at the first step because it has the lowest partial correlation of any variable given that all the other predictor variables are entered into the regression equation. The next variables eliminated, in order, were SMOKE, INCOMEC, and GENDER, resulting in a model with eight predictor variables and a multiple R of .981. Note that all variables in Model 5 were significant in the following table.
As before, the table of excluded values gives information about variables not in the regression equation at any point in time.
Note that none of these variables were significant in the final model.
Stepwise procedures allow the data to drive the theory. Some statisticians (I would have to include myself among them) object to the mindless application of statistical procedures to multivariate data.
There is no guarantee that the Forward and Backward procedures would agree on the same model if the options were set to different values so that the same number of variables were entered into the model. At some point a variable may no longer contribute to the regression model because of other variables in the model, even if it did contribute at an earlier point in time. For that reason SPSS provides methods of "STEPWISE" and "REMOVE" which test at each stage to see if a variable still belongs in the model. These methods could be considered a combination of Forward and Backward methods. Using them still does not guarantee that the methods will converge on a single regression model.
The manner is which regression weights are computed guarantee that they will provide an optimal fit with respect to the least square criterion for the existing set of data. If a statistician wishes to predict a different set of data, the regression weights are no longer optimal. There will be substantial shrinkage in the value of R2 if the weights estimated on one set of data are used on a second set of data. The amount of shrinkage can be estimated using a cross-validation procedure.
In cross-validation, regression weights are estimated using one set of data and are tested on a second set of data. If the regression weights estimated on the first set of data predict the second set of data, the weights are said to be cross-validated.
Suppose an industrial/organization psychologist wished to predict job success using four different test scores. The psychologist could collect the four test scores from a randomly selected group of job applicants. After hiring all the selected group of job applicants, regardless of their scores on the tests, a measure of success on the job is taken. Success on the job is now predicted from the four test scores using a multiple regression procedure. Stepwise procedures may be used to eliminate tests that are predicting similar variance in job success. In any case, the psychologist is now ready to predict job success from the test scores for a new set of job applicants.
Not so fast! Careful application of multiple regression methods require that the regression weights be cross-validated on a different set of job applicants. Another random sample of job applicants is taken. Each applicant is given the test battery and then hired, again regardless of what scores they made on the tests. After some time on the job a measure of job success is taken. Job success is then predicted by using the regression weights found using the first set of job applicants. If the new data is successfully predicted using old regression weights, the regression procedure is said to be cross-validated. It is expected that the accuracy of prediction will not be as good for the second set of data. This is because the regression procedure is subject to variances in data from sample to sample, called "error". The greater the error in the regression procedure, the greater the shrinkage of the value of R2.
The above procedure is an idealized method of the use of multiple regression. In many real life applications of the procedure, random samples of job applicants are not feasible. There may be considerable pressure from administration to select on the basis of the test battery for the first sample, let alone the second sample needed for cross-validation. In either case the multiple regression procedure is compromised. In most cases application of regression procedures to a selected rather than a random sample will result in poorer predictions. All this must be kept in mind when evaluating research on prediction models.
Multiple regression provides a powerful method to analyze multivariate data. Considerable caution, however, must be observed when interpreting the results of a multiple regression analysis. Personal recommendations include a theory that drives the selection of variables and cross-validation of the results of the analysis.