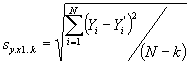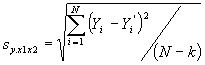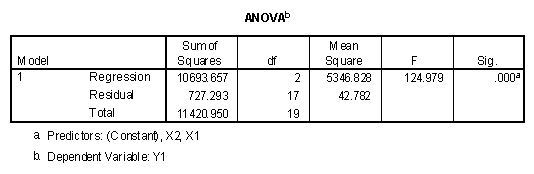Multiple regression is an extension of simple linear regression in which more than one independent variable (X) is used to predict a single dependent variable (Y). The predicted value of Y is a linear transformation of the X variables such that the sum of squared deviations of the observed and predicted Y is a minimum. The computations are more complex, however, because the interrelationships among all the variables must be taken into account in the weights assigned to the variables. The interpretation of the results of a multiple regression analysis is also more complex for the same reason.
With two independent variables the prediction of Y is expressed by the following equation:
Y'i = b0 + b1X1i + b2X2i
Note that this transformation is similar to the linear transformation of two variables discussed in the previous chapter except that the w's have been replaced with b's and the X'i has been replaced with a Y'i.
The "b" values are called regression weights and are computed in a way that minimizes the sum of squared deviations
in the same manner as in simple linear regression. The difference is that in simple linear regression only two weights, the intercept (b0) and slope (b1), were estimated, while in this case, three weights (b0, b1, and b2) are estimated.
The data used to illustrate the inner workings of multiple regression are presented below:
| Y1 | Y2 | X1 | X2 | X3 | X4 |
| 125 | 113 | 13 | 18 | 25 | 11 |
| 158 | 115 | 39 | 18 | 59 | 30 |
| 207 | 126 | 52 | 50 | 62 | 53 |
| 182 | 119 | 29 | 43 | 50 | 29 |
| 196 | 107 | 50 | 37 | 65 | 56 |
| 175 | 135 | 64 | 19 | 79 | 49 |
| 145 | 111 | 11 | 27 | 17 | 14 |
| 144 | 130 | 22 | 23 | 31 | 17 |
| 160 | 122 | 30 | 18 | 34 | 22 |
| 175 | 114 | 51 | 11 | 58 | 40 |
| 151 | 121 | 27 | 15 | 29 | 31 |
| 161 | 105 | 41 | 22 | 53 | 39 |
| 200 | 131 | 51 | 52 | 75 | 36 |
| 173 | 123 | 37 | 36 | 44 | 27 |
| 175 | 121 | 23 | 48 | 27 | 20 |
| 162 | 120 | 43 | 15 | 65 | 36 |
| 155 | 109 | 38 | 19 | 62 | 37 |
| 230 | 130 | 62 | 56 | 75 | 50 |
| 162 | 134 | 28 | 30 | 36 | 20 |
| 153 | 124 | 30 | 25 | 41 | 33 |
The example data can be obtained as a text file and as an SPSS data.
If a student desires a more concrete description of this data file, meaning could be given the variables as follows:
Y1 - A measure of success in graduate school.
X1 - A measure of intellectual ability.
X2 - A measure of "work ethic."
X3 - A second measure of intellectual ability.
X4 - A measure of spatial ability.
Y2 - Score on a major review paper.
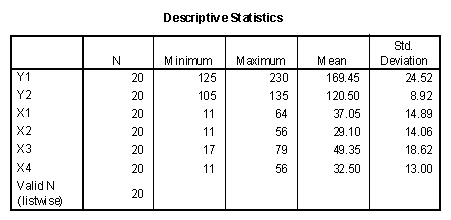
The first step in the analysis of multivariate data is a table of means and standard deviations. Additional analysis recommendations include histograms of all variables with a view for outliers, or scores that fall outside the range of the majority of scores. In a multiple regression analysis, these score may have a large "influence" on the results of the analysis and are a cause for concern. In the case of the example data, the following means and standard deviations were computed using SPSS by clicking Analyze/Summarize/Descriptives.
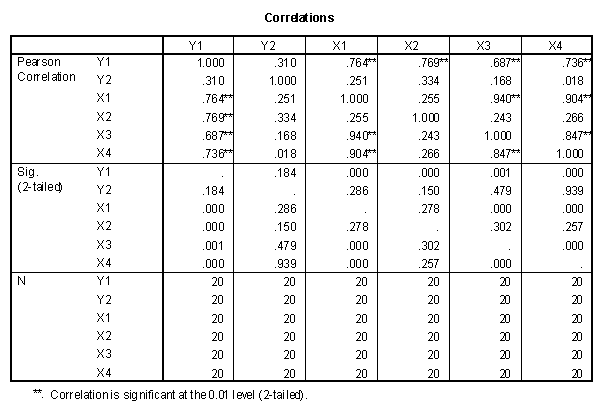
The second step is an analysis of bivariate relationships between variables. This can be done using a correlation matrix, generated using the Analyze/Correlate/Bivariate commands in SPSS.
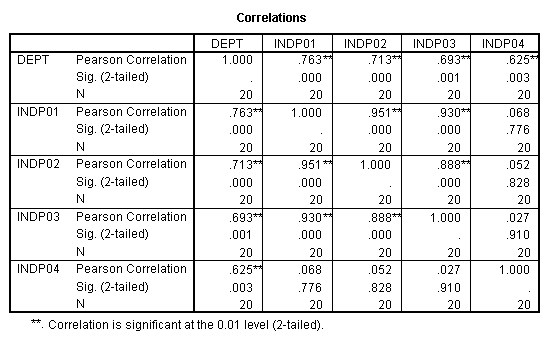
In the case of the example data, it is noted that all X variables correlate significantly with Y1, while none correlate significantly with Y2. In addition, X1 is significantly correlated with X3 and X4, but not with X2. Interpreting the variables using the suggested meanings, success in graduate school could be predicted individually with measures of intellectual ability, spatial ability, and work ethic. The measures of intellectual ability were correlated with one another. Measures of intellectual ability and work ethic were not highly correlated. The score on the review paper could not be accurately predicted with any of the other variables.
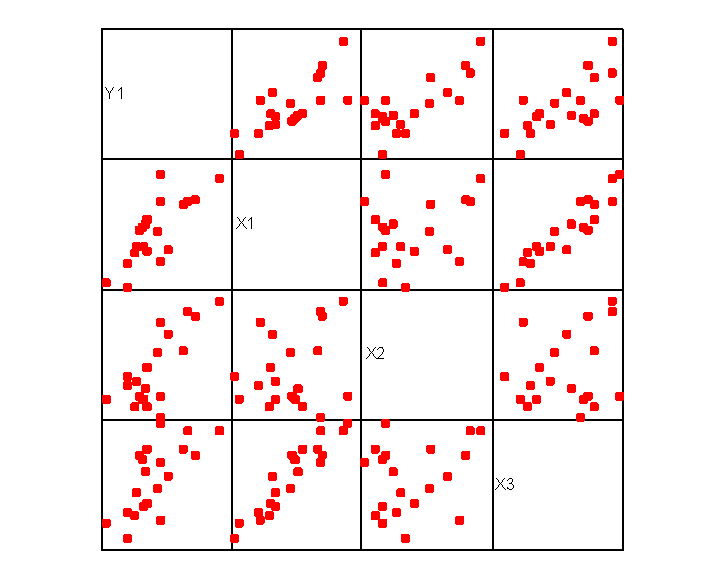
A visual presentation of the scatter plots generating the correlation matrix can be generated using the Graphs/Scatter/Matrix commands in SPSS.
These graphs may be examined for multivariate outliers that might not be found in the univariate view.
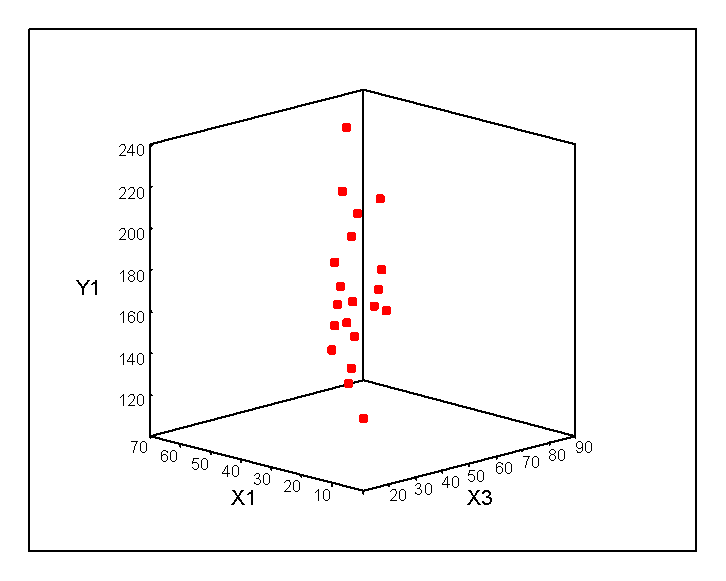
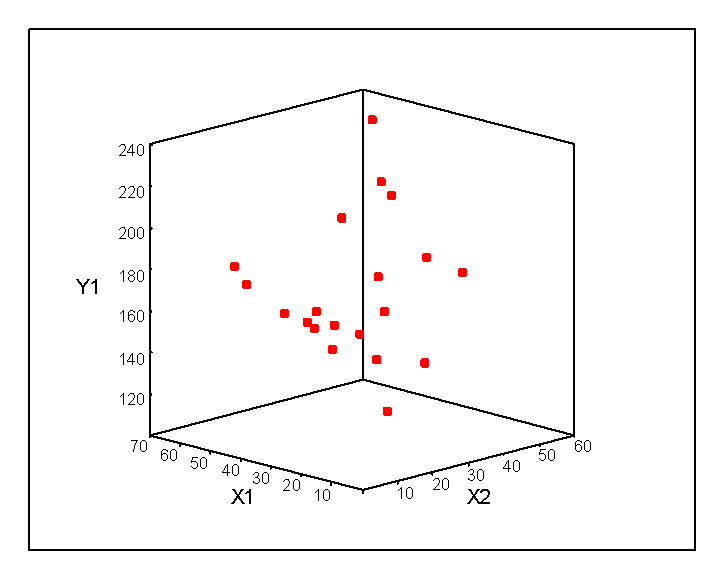
Three-dimensional scatter plots also permit a graphical representation in the same information as the multiple scatter plots. Using the Graphs/Scatter/3-D commands in SPSS results in the following two graphs.
The formulas to compute the regression weights with two independent variables are available from various sources (Pedhazur, 1997). They are messy and do not provide a great deal of insight into the mathematical "meanings" of the terms. For that reason, computational procedures will be done entirely with a statistical package.
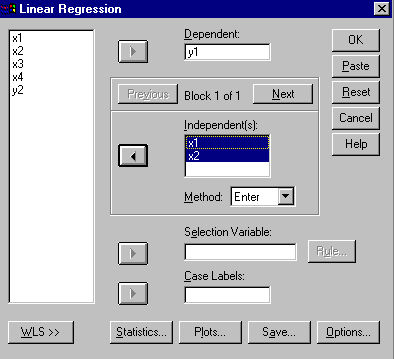
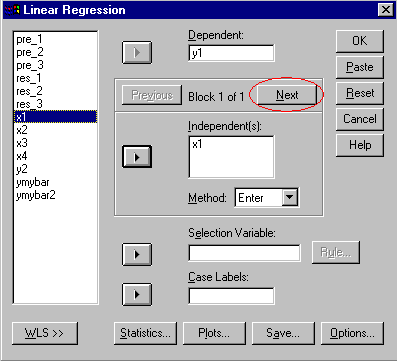
The multiple regression is done in SPSS by selecting Analyze/Regression/Linear. The interface should appear as follows:
In the first analysis, Y1 is the dependent variable and two independent variables are entered in the first block, X1 and X2. In addition, under the "Save..." option, both unstandardized predicted values and unstandardized residuals were selected.
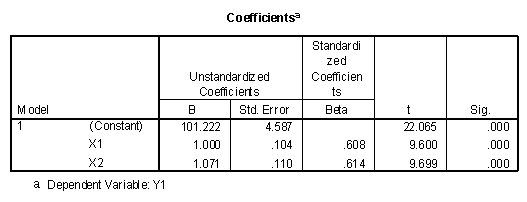
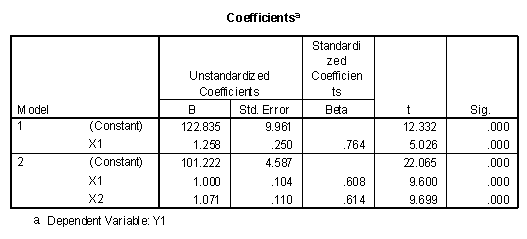
The output consists of a number of tables. The "Coefficients" table presents the optimal weights in the regression model, as seen in the following.
Recalling the prediction equation, Y'i = b0 + b1X1i + b2X2i, the values for the weights can now be found by observing the "B" column under "Unstandardized Coefficients." They are b0 = 101.222, b1 = 1.000, and b2 = 1.071, and the regression equation appears as:
Y'i = 101.222 + 1.000X1i + 1.071X2i
The "Beta" column under "Standardized Coefficients" gives similar information, except all values of X and Y have been standardized (set to mean of zero and standard deviation of one) before the weights are computed. In this case the value of b0 is always 0 and not included in the regression equation. The equation and weights for the example data appear below.
ZY = b 1 ZX1 + b 2 ZX2
ZY = .608 ZX1 + .614 ZX2
The standardization of all variables allows a better comparison of regression weights, as the unstandardized weights are a function of the variance of both the Y and the X variables.
The values of Y1i can now be predicted using the following linear transformation.
Y'1i = 101.222 + 1.000X1i + 1.071X2i
Thus, the value of Y1i where X1i = 13 and X2i = 18 for the first student could be predicted as follows.
Y'11 = 101.222 + 1.000X11 + 1.071X21
Y'11 = 101.222 + 1.000 * 13 + 1.071 * 18
Y'11 = 101.222 + 13.000 + 19.278
Y'11 = 133.50
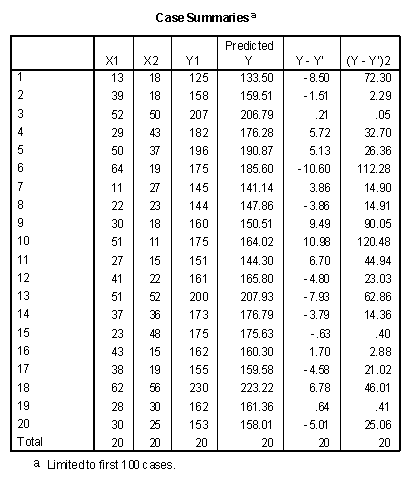
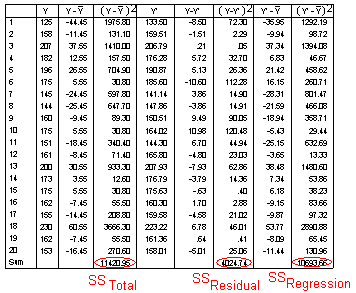
The scores for all students are presented below, as computed in the data file of SPSS. Note that the predicted Y score for the first student is 133.50. The predicted Y and residual values are automatically added to the data file when the unstandardized predicted values and unstandardized residuals are selected using the "Save" option.
The difference between the observed and predicted score, Y-Y ', is called a residual. This column has been computed, as has the column of squared residuals. The squared residuals (Y-Y')2 may be computed in SPSS by squaring the residuals using Transform/Compute commands.
The analysis of residuals can be informative. The larger the residual for a given observation, the larger the difference between the observed and predicted value of Y and the greater the error in prediction. In the example data, the regression under-predicted the Y value for observation 10 by a value of 10.98, and over-predicted the value of Y for observation 6 by a value of 10.60. In some cases the analysis of errors of prediction in a given model can direct the search for additional independent variables that might prove valuable in more complete models.
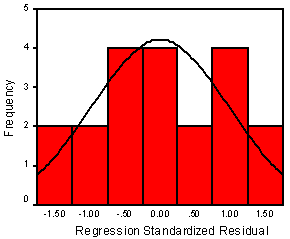
The residuals are assumed to be normally distributed when the testing of hypotheses using analysis of variance (R2 change). Although analysis of variance is fairly robust with respect to this assumption, it is a good idea to examine the distribution of residuals, especially with respect to outliers. The distribution of residuals for the example data is presented below.
The multiple correlation coefficient, R, is the correlation coefficient between the observed values of Y and the predicted values of Y. For this reason, the value of R will always be positive and will take on a value between zero and one. The direction of the multivariate relationship between the independent and dependent variables can be observed in the sign, positive or negative, of the regression weights. The interpretation of R is similar to the interpretation of the correlation coefficient, the closer the value of R to one, the greater the linear relationship between the independent variables and the dependent variable.
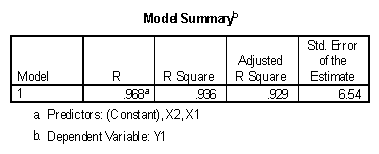
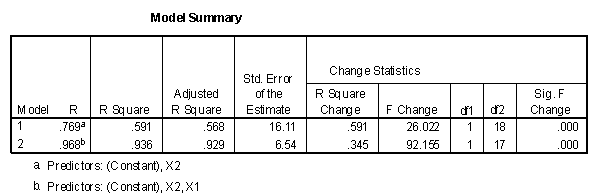
The value of R can be found in the "Model Summary" table of the SPSS output. In the case of the example data, the value for the multiple R when predicting Y1 from X1 and X2 is .968, a very high value.
The multiple correlation coefficient squared ( R2 ) is also called the coefficient of determination. It may be found in the SPSS output alongside the value for R. The interpretation of R2 is similar to the interpretation of r2, namely the proportion of variance in Y that may be predicted by knowing the value of the X variables. The value for R squared will always be less than the value for R. In general the value of multiple R is to be preferred over R squared as a measure of relationship because R squared is measured in units of measurement squared while R is in terms of units of measurement.
The adjustment in the "Adjusted R Square" value in the output tables is a correction for the number of X variables included in the prediction model. In general, the smaller the N and the larger the number of variables, the greater the adjustment. In the example data, the results could be reported as "92.9% of the variance in the measure of success in graduate school can be predicted by measures of intellectual ability and work ethic."
The standard error of estimate is a measure of error of prediction. The definitional formula for the standard error of estimate is an extension of the definitional formula in simple linear regression and is presented below.
The difference between this formula and the formula presented in an earlier chapter is in the denominator of the equation. In both cases the denominator is N - k, where N is the number of observations and k is the number of parameters which are estimated to find the predicted value of Y. In the case of simple linear regression, the number of parameters needed to be estimated was two, the intercept and the slope, while in the case of the example with two independent variables, the number was three, b0, b1, and b2.
The computation of the standard error of estimate using the definitional formula for the example data is presented below. The numerator, or sum of squared residuals, is found by summing the (Y-Y')2 column.
Note that the value for the standard error of estimate agrees with the value given in the output table of SPSS.
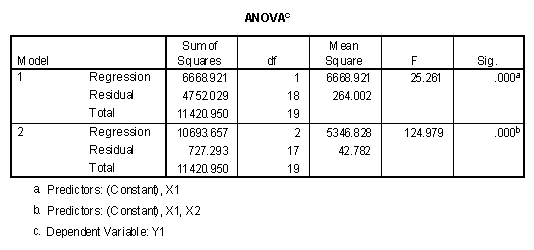
The ANOVA table output when both X1 and X2 are entered in the first block when predicting Y1 appears as follows.
Because the exact significance level is less than alpha, in this case assumed to be .05, the model with variables X1 and X2 significantly predicted Y1. As described in the chapter on testing hypotheses using regression, the Sum of Squares for the residual, 727.29, is the sum of the squared residuals (see the standard error of estimate above). The mean square residual, 42.78, is the squared standard error of estimate. The total sum of squares, 11420.95, is the sum of the squared differences between the observed values of Y and the mean of Y. The regression sum of squares, 10693.66, is the sum of squared differences between the model where Y'i = b0 and Y'i = b0 + b1X1i + b2X2i. The regression sum of squares is also the difference between the total sum of squares and the residual sum of squares, 11420.95 - 727.29 = 10693.66. The regression mean square, 5346.83, is computed by dividing the regression sum of squares by its degrees of freedom. In this case the regression mean square is based on two degrees of freedom because two additional parameters, b1 and b2, were computed.
The following table illustrates the computation of the various sum of squares in the example data.
Note that this table is identical in principal to the table presented in the chapter on testing hypotheses in regression.
When more terms are added to the regression model, the regression weights change as a function of the relationships between both the independent variables and the dependent variable. This can be illustrated using the example data.
A minimal model, predicting Y1 from the mean of Y1 results in the following.
Y'i = b0
Y'i = 169.45
A partial model, predicting Y1 from X1 results in the following model.
Y'i = b0 + b1X1i
Y'i = 122.835 + 1.258 X1i
A second partial model, predicting Y1 from X2 is the following.
Y'i = b0 + b2X2I
Y'i = 130.425 + 1.341 X2i
As established earlier, the full regression model when predicting Y1 from X1 and X2 is
Y'i = b0 + b1X1i + b2X2i
Y'i = 101.222 + 1.000X1i + 1.071X2i
As can be observed, the values of both b1 and b2 change when both X1 and X2 are included in the regression model. The size and effect of these changes are the foundation for the significance testing of sequential models in regression.
The unadjusted R2 value will increase with the addition of terms to the regression model. The amount of change in R2 is a measure of the increase in predictive power of the independent variable or variables, given the independent variable or variables already in the model. For example, the effect of work ethic (X2) on success in graduate school (Y1) could be assessed given one already has a measure of intellectual ability (X1.) The following table presents the results for the example data.
| Variables in Equation | R2 | Increase in R2 |
|---|---|---|
| None | 0.00 | - |
| X1 | .584 | .584 |
| X1, X2 | .936 | .352 |
A similar table can be constructed to evaluate the increase in predictive power of X3 given X1 is already in the model.
As can be seen, although both X2 and X3 individually correlate significantly with Y1, X2 contributes a fairly large increase in predictive power in combination with X1, while X3 does not. Because X1 and X3 are highly correlated with each other, knowledge of one necessarily implies knowledge of the other. In regression analysis terms, X2 in combination with X1 predicts unique variance in Y1, while X3 in combination with X1 predicts shared variance.
It is possible to do significance testing to determine whether the addition of another dependent variable to the regression model significantly increases the value of R2. This significance test is the topic of the next section.
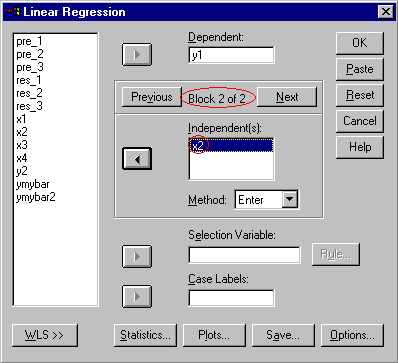
In order to test whether a variable adds significant predictive power to a regression model, it is necessary to construct the regression model in stages or blocks. This is accomplished in SPSS by entering the independent variables in different blocks. For example, if the increase in predictive power of X2 after X1 has been entered in the model was desired, then X1 would be entered in the first block and X2 in the second block. The following demonstrates how to construct these sequential models. The figure below illustrates how X1 is entered in the model first.
The next figure illustrates how X2 is entered in the second block.
In order to obtain the desired hypothesis test, click on the "Statistics..." button and then select the "R squared change" option, as presented below.
The additional output obtained by selecting these option include a model summary,
an ANOVA table,
and a table of coefficients.
The only new information presented in these tables is in the model summary and the "Change Statistics" entries. The critical new entry is the test of the significance of R2 change for model 2. In this case the change is statistically significant. It could be said that X2 adds significant predictive power in predicting Y1 after X1 has been entered into the regression model.
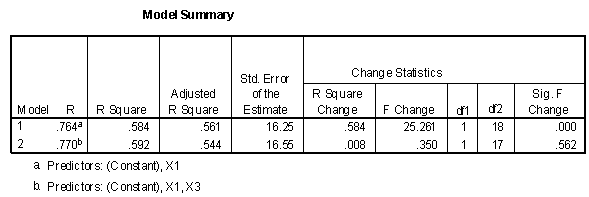
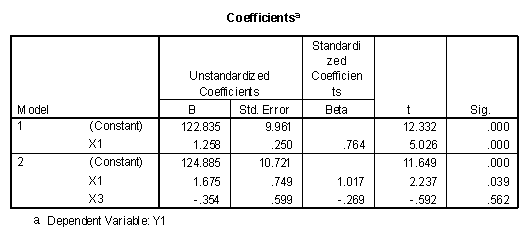
Conducting a similar hypothesis test for the increase in predictive power of X3 when X1 is already in the model produces the following model summary table.
Note that in this case the change is not significant. The table of coefficients also presents some interesting relationships.
Note that the "Sig." level for the X3 variable in model 2 (.562) is the same as the "Sig. F Change" in the preceding table. The interpretation of the "Sig." level for the "Coefficients" is now apparent. It is the significance of the addition of that variable given all the other independent variables are already in the regression equation. Note also that the "Sig. " Value for X1 in Model 2 is .039, still significant, but less than the significance of X1 alone (Model 1 with a value of .000). Thus a variable may become "less significant" in combination with another variable than by itself.
The regression equation, Y'i = b0 + b1X1i + b2X2i, defines a plane in a three dimensional space. If all possible values of Y were computed for all possible values of X1 and X2, all the points would fall on a two-dimensional surface. This surface can be found by computing Y' for three arbitrarily (X1, X2) pairs of data, plotting these points in a three-dimensional space, and then fitting a plane through the points in the space. The plane is represented in the three-dimensional rotating scatter plot as a yellow surface.
The residuals can be represented as the distance from the points to the plane parallel to the Y-axis. Residuals are represented in the rotating scatter plot as red lines.
Graphically, multiple regression with two independent variables fits a plane to a three-dimensional scatter plot such that the sum of squared residuals is minimized. The multiple regression plane is represented below for Y1 predicted by X1 and X2.
A similar relationship is presented below for Y1 predicted by X1 and X3.
Sub window_onLoad() document.X12YP.RegressionLine 0.6, 0.6, .25, .25 document.X13YP.RegressionLine 0.6, 0.6, .45, .85 end sub
While humans have difficulty visualizing data with more than three dimensions, mathematicians have no such problem in mathematically thinking about with them. When dealing with more than three dimensions, mathematicians talk about fitting a hyperplane in hyperspace.
With three variable involved, X1, X2, and Y, many varieties of relationships between variables are possible. It will prove instructional to explore three such relationships.
In this example, both X1 and X2 are correlated with Y, and X1 and X2 are uncorrelated with each other. In the example data, X1 and X2 are correlated with Y1 with values of .764 and .769 respectively. The independent variables, X1 and X2, are correlated with a value of .255, not exactly zero, but close enough. In this case X1 and X2 contribute independently to predict the variability in Y. It doesn't matter much which variable is entered into the regression equation first and which variable is entered second.
The following table of R square change predicts Y1 with X1 and then with both X1 and X2.
The next table of R square change predicts Y1 with X2 and then with both X1 and X2.
The value of R square change for X1 from Model 1 in the first case (.584) to Model 2 in the second case (.345) is not identical, but fairly close. If the correlation between X1 and X2 had been 0.0 instead of .255, the R square change values would have been identical.
Because of the structure of the relationships between the variables, slight changes in the regression weights would rather dramatically increase the errors in the fit of the plane to the points.
In this case, both X1 and X2 are correlated with Y, and X1 and X2 are correlated with each other. In the example data, X1 and X3 are correlated with Y1 with values of .764 and .687 respectively. The independent variables, X1 and X3, are correlated with a value of .940. In this situation it makes a great deal of difference which variable is entered into the regression equation first and which is entered second.
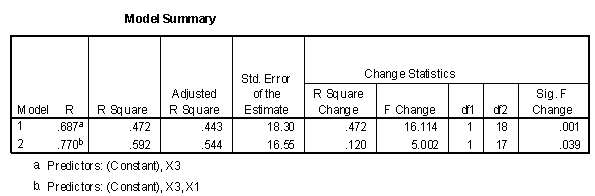
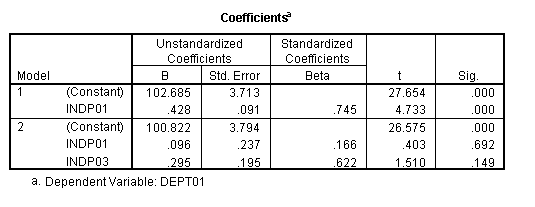
Entering X1 first and X3 second results in the following R square change table.
Entering X3 first and X1 second results in the following R square change table.
As before, both tables end up at the same place, in this case with an R2 of .592. In this case, however, it makes a great deal of difference whether a variable is entered into the equation first or second. Variable X3, for example, if entered first has an R square change of .561. If entered second after X1, it has an R square change of .008. In the first case it is statistically significant, while in the second it is not.
As two independent variables become more highly correlated, the solution to the optimal regression weights becomes unstable. This can be seen in the rotating scatter plots of X1, X3, and Y1. The plane that models the relationship could be modified by rotating around an axis in the middle of the points without greatly changing the degree of fit. The solution to the regression weights becomes unstable. That is, there are any number of solutions to the regression weights which will give only a small difference in sum of squared residuals. This is called the problem of multicollinearity in mathematical vernacular.
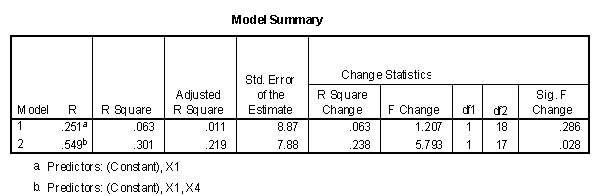
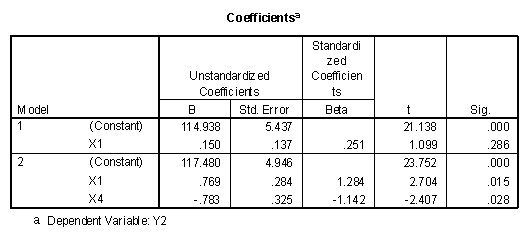
One of the many varieties of relationships occurs when neither X1 nor X2 individually correlates with Y, X1 correlates with X2, but X1 and X2 together correlate highly with Y. This phenomena may be observed in the relationships of Y2, X1, and X4. In the example data neither X1 nor X4 is highly correlated with Y2, with correlation coefficients of .251 and .018 respectively. Variables X1 and X4 are correlated with a value of .847. Fitting X1 followed by X4 results in the following tables.
In this case, the regression weights of both X1 and X4 are significant when entered together, but insignificant when entered individually. It is also noted that the regression weight for X1 is positive (.769) and the regression weight for X4 is negative (-.783). In this case the variance in X1 that does not account for variance in Y2 is cancelled or suppressed by knowledge of X4. Variable X4 is called a suppressor variable.
In terms of the descriptions of the variables, if X1 is a measure of intellectual ability and X4 is a measure of spatial ability, it might be reasonably assumed that X1 is composed of both verbal ability and spatial ability. If the score on a major review paper is correlated with verbal ability and not spatial ability, then subtracting spatial ability from general intellectual ability would leave verbal ability. Thus the high multiple R when spatial ability is subtracted from general intellectual ability. It is for this reason that X1 and X4, while not correlated individually with Y2, in combination correlate fairly highly with Y2.
Multiple regression predicting a single dependent variable with two independent variables is conceptually similar to simple linear regression, predicting a single dependent variable with a single independent variable, except more weights are estimated and rather than fitting a line in a two-dimensional scatter plot, a plane is fitted to describe a three-dimensional scatter plot. Interpretation of the results is confounded by both the relationship between the two independent variables and their relationship with dependent variable.
A variety of relationships and interactions between the variables were then explored. These relationships discussed barely scratched the surface of the possibilities. Suffice it to say that the more variables that are included in an analysis, the greater the complexity of the analysis. Multiple regression is usually done with more than two independent variables. The next chapter will discuss issues related to more complex regression models.