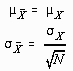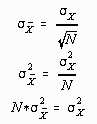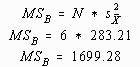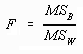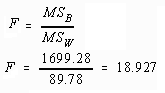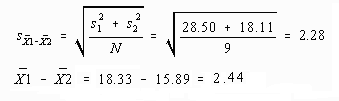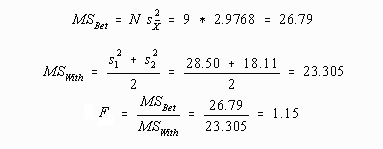
Multiple comparisons using t-tests is not the analysis of choice. An example can illustrate why.
Suppose a researcher performs a study on the effectiveness of various methods of individual therapy. The methods used are Reality Therapy, Behavior Therapy, Psychoanalysis, Gestalt Therapy, and, of course, a control group. Twenty patients are randomly assigned to each group. At the conclusion of the study, changes in self-concept are found for each patient. The purpose of the study was to determine if one method was more effective than the other methods in improving patients' self-concept.
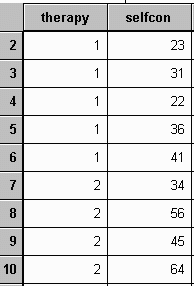
At the conclusion of the experiment the researcher creates a data file in SPSS in the following manner:
The researcher wants to compare the means of the groups to decide about the effectiveness of the therapy.
One method of performing this analysis is by doing all possible t-tests, called multiple t-tests. That is, Reality Therapy is first compared with Behavior Therapy, then Psychoanalysis, then Gestalt Therapy, and then the Control Group. Behavior Therapy is then individually compared with the last three groups, and so on. Using this procedure ten different t-tests would be performed. Therein lies the difficulty with multiple t-tests.
First, because the number of t-tests increases geometrically as a function of the number of groups, analysis becomes cognitively difficult somewhere in the neighborhood of seven different tests. An analysis of variance organizes and directs the analysis, allowing easier interpretation of results.
Second, by doing a greater number of analyses, the probability of committing at least one Type I error somewhere in the analysis greatly increases. The probability of committing at least one Type I error in an analysis is called the experiment-wise error rate. The researcher may want to perform a fewer number of hypothesis tests in order to reduce the experiment-wise error rate. The ANOVA procedure performs this function.
In this case, the correct analysis in SPSS is a one-way Analysis of Variance or ANOVA. Begin the procedure by selecting Statistics/Compare Means/One-Way ANOVA, as the following figure illustrates.
Then select the variables and options, as shown in this figure:
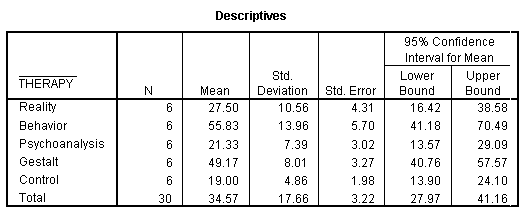
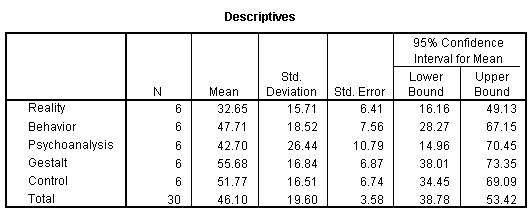
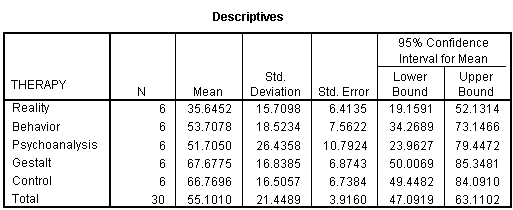
When you check the Descriptive box in the Statistics section of the One-Way ANOVA: Options dialog box (shown in the preceding figure), the result is a table of means and standard deviations, such as the following:
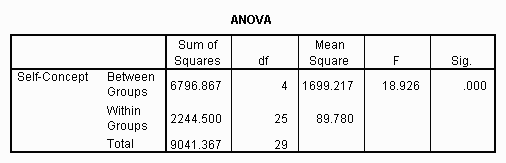
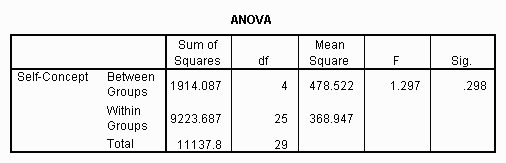
The results of the ANOVA are presented in an ANOVA table, which has columns labeled Sum of Squares (sometimes referred to as SS), df (degrees of freedom), Mean Square (sometimes referred to as MS), F (for F-ratio), and Sig. The only column that is critical for interpretation is the last (Sig.)! The others are used mainly for intermediate computational purposes. Here's an example of an ANOVA table:
The row labeled "Between Groups", having a probability value associated with it, is the only one of any great importance at this time. The other rows are used mainly for computational purposes. The researcher would most probably first look at the exact significance level value of ".000" located under the "Sig." column. As discussed previously, the exact significance level is not really zero, but some number too small to show up in the number of decimals presented in the SPSS output
Of all the information presented in the ANOVA table, the major interest of the researcher will most likely be focused on the value located in the "Sig." column, because this is the exact significance level of the ANOVA. If the number (or numbers) found in this column is (are) less than the critical value of alpha (a) set by the experimenter, then the effect is said to be significant. Since this value is usually set at .05, any value less than this will result in significant effects, while any value greater than this value will result in non significant effects. In the example shown in the previous figure, the exact significance is .000, so the effects would be statistically significant. (As discussed earlier in this text, the exact significance level is not really zero, but is some number too small to show up in the number of decimals presented in the SPSS output.)
Using this procedure, finding significant effects implies that the means differ more than would be expected by chance alone. In terms of the previous experiment, it would mean that the treatments were not equally effective. This table does not tell the researcher anything about what the effects were, just that there most likely were real effects.
If the effects are found to be non significant, then the differences between the means are not great enough to allow the researcher to rule out a chance or sampling error explanation. In that case, no further interpretation is attempted.
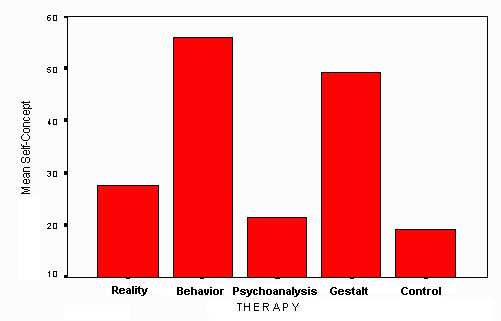
When the effects are significant, the means must then be examined in order to determine the nature of the effects. There are procedures called post-hoc tests to assist the researcher in this task, but often the reason is fairly obvious by looking at the size of the various means. For example, in the preceding analysis, Gestalt Therapy and Behavior Therapy were the most effective in terms of mean improvement.
In the case of significant effects, a graphical presentation of the means can sometimes assist in analysis. The following figure shows a graph of mean values from the preceding analysis.
In order to explain why the ANOVA hypothesis testing procedure works to simultaneously find effects among any number of means, the following presents the theory of ANOVA.
First, a review of the sampling distribution is necessary. (If you have difficulty with this summary, please go back and read the Chapter 17, "The Sampling Distribution.")
A sample is a finite number (N) of scores. Sample statistics are numbers that describe the sample. Example statistics are the mean (![]() ), mode (Mo), median (Md), and standard deviation (sX).
), mode (Mo), median (Md), and standard deviation (sX).
Probability models exist in a theoretical world where complete information is unavailable. As such, they can never be known except in the mind of the mathematical statistician. If an infinite number of infinitely precise scores were taken, the resulting distribution would be a probability model of the population. Models of scores are characterized by parameters. Two common parameters are mand d.
Sample statistics are used as estimators of the corresponding parameters in the model. For example, the mean and standard deviation of the sample are used as estimates of the corresponding parameters
![]() and
and
![]() .
.
The sampling distribution is a distribution of a sample statistic. It is a model of a distribution of scores, like the population distribution, except that the scores are not raw scores, but statistics. It is a thought experiment: "What would the world be like if a person repeatedly took samples of size N from the population distribution and computed a particular statistic each time?" The resulting distribution of statistics is called the sampling distribution of that statistic.
The sampling distribution of the mean is a special case of a sampling distribution. It is a distribution of sample means, described with the parameters
![]() and
and
![]() . These parameters are closely related to the parameters of the population distribution, the relationship being described by the Central Limit Theorem. This theorem essentially states that the mean of the sampling distribution of the mean (
. These parameters are closely related to the parameters of the population distribution, the relationship being described by the Central Limit Theorem. This theorem essentially states that the mean of the sampling distribution of the mean (
![]() ) equals the mean of the model of scores (
) equals the mean of the model of scores (
![]() ), and that the standard error of the mean (
), and that the standard error of the mean (
![]() ) equals the theoretical standard deviation of the model of scores (
) equals the theoretical standard deviation of the model of scores (
![]() ) divided by the square root of N. These relationships may be summarized as follows:
) divided by the square root of N. These relationships may be summarized as follows:
When the data have been collected from more than one sample, there are two independent methods of estimating the parameter
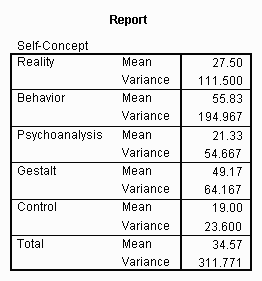
![]() ,the between and the within method. The collected data are usually first described with sample statistics, as demonstrated in the following example:
,the between and the within method. The collected data are usually first described with sample statistics, as demonstrated in the following example:
The Total mean and variance is the mean and variance of all 100 scores in the sample.
Since each of the sample variances may be considered an independent estimate of the parameter
![]() , finding the mean of the variances provides a method of combining the separate estimates of
, finding the mean of the variances provides a method of combining the separate estimates of
![]() into a single value. The resulting statistic is called the Mean Squares Within, often represented by MSW. It is called the within method because it computes the estimate by combining the variances within each sample. In the previous example, the Mean Squares Within would be equal to 89.78 or the mean of 111.5, 194.97, 54.67, 64.17, and 23.6. The following formula defines the Mean Squares Within as the mean of the variances.
into a single value. The resulting statistic is called the Mean Squares Within, often represented by MSW. It is called the within method because it computes the estimate by combining the variances within each sample. In the previous example, the Mean Squares Within would be equal to 89.78 or the mean of 111.5, 194.97, 54.67, 64.17, and 23.6. The following formula defines the Mean Squares Within as the mean of the variances.
The parameter
![]() may also be estimated by comparing the means of the different samples, but the logic is slightly less straightforward and employs both the concept of the sampling distribution and the Central Limit Theorem.
may also be estimated by comparing the means of the different samples, but the logic is slightly less straightforward and employs both the concept of the sampling distribution and the Central Limit Theorem.
First, the standard error of the mean squared (
![]() ) is the theoretical variance of a distribution of sample means. In a real-life situation where there is more than one sample, the variance of the sample means may be used as an estimate of the standard error of the mean squared (
) is the theoretical variance of a distribution of sample means. In a real-life situation where there is more than one sample, the variance of the sample means may be used as an estimate of the standard error of the mean squared (
![]() ). This is analogous to the situation where the variance of the sample (s2) is used as an estimate of d2.
). This is analogous to the situation where the variance of the sample (s2) is used as an estimate of d2.
In this case the sampling distribution consists of an infinite number of means and the real-life data consists of A (in this case 5) means. The computed statistic is thus an estimate of the theoretical parameter.
The relationship between the standard error of the mean and the sigma of the model of scores expressed in the Central Limit Theorem may now be used to obtain an estimate of ? 2. First both sides of the equation are squared and then multiplied by N, resulting in the following transformation:
![]() .
.
Thus the variance of the population may be found by multiplying the standard error of the mean squared (
![]() ) by N, the size of each sample.
) by N, the size of each sample.
Since the variance of the means,
![]() , is an estimate of the standard error of the mean squared,
, is an estimate of the standard error of the mean squared,
![]() , the theoretical variance of the model,
, the theoretical variance of the model, ![]() , may be estimated by multiplying the size of each sample, N, by the variance of the sample means. This value is called the Mean Squares Between and is often symbolized by MSB. The computational procedure for MSB is presented here:
, may be estimated by multiplying the size of each sample, N, by the variance of the sample means. This value is called the Mean Squares Between and is often symbolized by MSB. The computational procedure for MSB is presented here:
The expressed value is called the Mean Squares Between because it uses the variance between the sample means to compute the estimate. Using this procedure on the example data yields:
At this point it has been established that there are two methods of estimating ![]() , Mean Squares Within and Mean Squares Between. It could also be demonstrated that these estimates are independent. Because of this independence, when both mean squares are computed using the same data set, different estimates will result. For example, in the presented data MSW=89.78 while MSB=1699.28. This difference provides the theoretical background for the F-ratio and ANOVA.
, Mean Squares Within and Mean Squares Between. It could also be demonstrated that these estimates are independent. Because of this independence, when both mean squares are computed using the same data set, different estimates will result. For example, in the presented data MSW=89.78 while MSB=1699.28. This difference provides the theoretical background for the F-ratio and ANOVA.
A new statistic, called the F-ratio is computed by dividing the MSB by MSW. This is illustrated by the following formula:
Using the example data described earlier the computed F-ratio becomes
The F-ratio can be thought of as a measure of how different the means are relative to the variability within each sample. As such, the F-ratio is a measure of the size of the effects. The larger this value, the greater the likelihood that the differences between the means are due to something other than chance alone, namely real effects. How big this F-ratio needs to be in order to make a decision about the reality of effects is the next topic of discussion.
If the difference between the means is due only to chance, that is, there are no real effects, then the expected value of the F-ratio would be one (1.00). This is true because both the numerator and the denominator of the F-ratio are estimates of the same parameter, d2. Seldom will the F-ratio be exactly equal to 1.00, however, because the numerator and the denominator are estimates rather than exact values. Therefore, when there are no effects the F-ratio will sometimes be greater or less than one.
To review, the basic procedure used in hypothesis testing is that a model is created in which the experiment is repeated an infinite number of times when there are no effects. A sampling distribution of a statistic is used as the model of what the world would look like if there were no effects. The result of the experiment, measured using a statistic, is compared with what would be expected given the model of no effects is true. If the computed statistic is unlikely given the model, then the model is rejected, along with the hypothesis that there were no effects.
In an ANOVA, the F-ratio is the statistic used to test the hypothesis that the effects are real: in other words, that the means are significantly different from one another. Before the details of the hypothesis test may be presented, the sampling distribution of the F-ratio must be discussed.
If the experiment were repeated an infinite number of times, each time computing the F-ratio, and there were no effects, the resulting distribution could be described by the F-distribution. The F-distribution is a theoretical probability distribution characterized by two parameters, df1 and df2, both of which affect the shape of the distribution. Since the F-ratio must always be positive, the F-distribution is non-symmetrical, skewed in the positive direction.
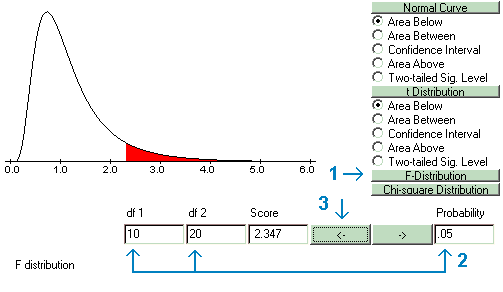
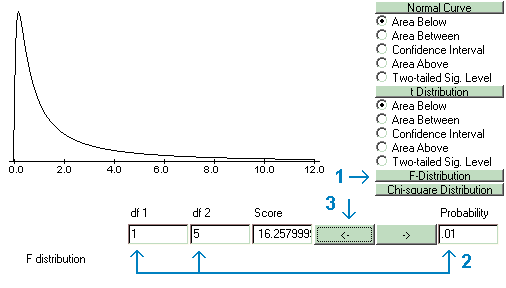
The F-ratio, which cuts off various proportions of the distributions, may be found for different values of df1 and df2. These F-ratios are called Fcrit values and may be found with the Probability Calculator by selecting F-Distribution; entering the appropriate values for degrees of freedom and probabilities; and then clicking the arrow pointing to the right.
Following are two examples of using the Probability Calculator to find an Fcrit. In the first, df1=10, df2=25, and alpha=.05; and in the second, with df1=1, df2=5, and alpha=.01. In the first example, the value of Fcrit = 2.437, and in the second, Fcrit =16.258.
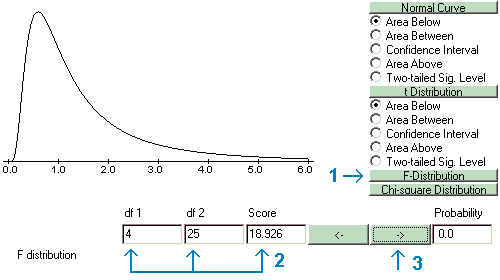
The exact significance level of any F-ratio relative to a given F distribution can be found using the Probability Calculator. Select the F Distribution, enter the appropriate degrees of freedom and the F-ratio that was found; and then click the arrow pointing to the right. The use of the Probability Calculator to find the exact significance level for the example F-ratio (18.962) described earlier in this chapter is presented here.
As in the SPSS ANOVA output of this data you saw earlier, the probability or exact significance level is too small to register within the decimals allowed in the display, so a value of zero is presented. The null hypothesis would be rejected and the alternative hypothesis accepted, because the exact significance level is less than alpha. The exact significance level found using the Probability Calculator and SPSS should be similar.
Probability Calculator
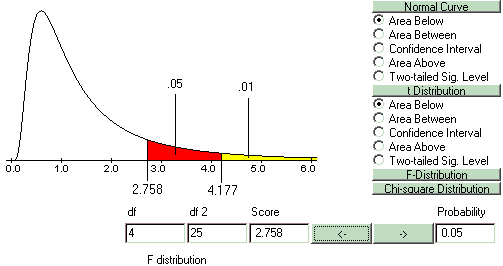
Theoretically, when there are no real effects, the F-distribution is an accurate model of the distribution of F-ratios. The F-distribution will have the parameters df1=A-1 (where A-1 is the number of different groups minus one) and df2=A(N-1), where A is the number of groups and N is the number in each group. In this case, an assumption is made that sample size is equal for each group. For example, if five groups of six subjects each were run in an experiment, and there were no effects, the F-ratios would be distributed with df1= A-1 = 5-1 = 4 and df2= A(N-1) = 5(6-1)=5*5=25. You can see a visual representation of this in the following figure:
When there are real effects, that is, the means of the groups are different due to something other than chance, the F-distribution no longer describes the distribution of F-ratios. In almost all cases, the observed F-ratio will be larger than would be expected when there were no effects. Take a look at the rationale for this situation.
First, an assumption is made that any effects are an additive transformation of the score. That is, the scores for each subject in each group can be modeled as a constant ( aa - the effect) plus error (eae). The scores would appear as:
where Xae is the score for Subject e in group a, aa is the size of the effect, and eae is the size of the error. The eae, or error, is different for each subject, while aa is constant within a given group.
As described in the chapter on transformations, an additive transformation changes the mean, but not the standard deviation or the variance. Because the variance of each group is not changed by the nature of the effects, the Mean Squares Within, as the mean of the variances, is not affected. The Mean Squares Between, as N times the variance of the means, will in most cases become larger because the variance of the means will most likely increase.
Imagine three individuals taking a test. An instructor first finds the variance of the three scores. He then adds five points to one random individual and subtracts five from another random individual. In most cases the variance of the three test score will increase, although it is possible that the variance could decrease if the points were added to the individual with the lowest score and subtracted from the individual with the highest score. If the constant added and subtracted was 30 rather than 5, then the variance would almost certainly be increased. Thus, the greater the size of the constant, the greater the likelihood of a larger increase in the variance.
With respect to the sampling distribution, the model differs depending upon whether or not there are effects. The difference is presented in the following figure:
Since the MSB usually increases and MSW remains the same, the F-ratio (F=MSB/MSW) will most likely increase. If there are real effects, the F-ratio obtained from the experiment will most likely be larger than the critical level from the F-distribution. The greater the size of the effects, the larger the obtained F-ratio is likely to become.
Thus, when there are no effects, the obtained F-ratio will be distributed as an F-distribution that may be specified. If effects exist, the obtained F-ratio will most likely become larger. By comparing the obtained F-ratio with that predicted by the model of no effects, a hypothesis test may be performed to decide on the reality of effects. If the exact significance level of the F-ratio is less than the value set for alpha, the decision will be that the effects are real. If not, then no decision about the reality of effects can be made.
When the number of groups (A) equals two (2), application of either the ANOVA or t-test procedures will result in identical exact significance levels. This equality is demonstrated in the following example:
Here is the example data for two groups:
| Group |
|
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 12 | 23 | 14 | 21 | 19 | 23 | 26 | 11 | 16 | 18.33 | 28.50 |
| 2 | 10 | 17 | 20 | 14 | 23 | 11 | 14 | 15 | 19 | 15.89 | 18.11 |
Finding an exact significance level using the Probability Calculator's Two-tailed Sig. Level under the t-Distribution with 16 degrees of freedom, a mu equal to zero, sigma equal to 2.28, and the value equal to 2.44 yields a probability or exact significance level of .30.
Using the F-Distribution option of the Probability Calculator with values of 1 and 16 for the degrees of freedom and 1.15 for the value results in an exact probability value of .30.
Because the t-test is a special case of the ANOVA and will always yield similar results, most researchers perform the ANOVA because the technique is much more powerful in analysis of complex experimental designs.
Given the following data for five groups, perform an ANOVA:
The ANOVA summary table that results should look like this:
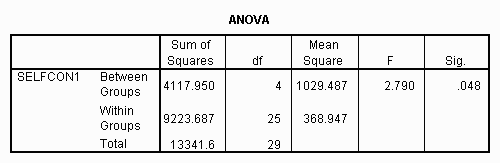
Since the exact significance level (.298) provided in SPSS output, is greater than alpha (.05) the results are not statistically significant.
Given the following data for five groups, perform an ANOVA. Note that the numbers are similar to the previous example except that three has been added to each score in Group 1, six to Group 2, nine to Group 3, twelve to Group 4, and fifteen to Group 5. This is equivalent to adding effects (aa) to the scores. Note that the means change, but the variances do not.
The SPSS ANOVA output table should look like this:
In this case, the "Sig." value (.048) is less than .05 and the null hypothesis must be rejected. If the alpha level had been set at .01, or even .045, the results of the hypothesis test would not be statistically significant. In classical hypothesis testing, however, there is no such thing as "close"; the results are either significant or not significant. In practice, however, researchers will often report the exact significance level and let the reader set his or her own significance level. When this is done the distinction between Bayesian and Classical Hypothesis Testing approaches becomes somewhat blurred. (Personally I think that anything that gives the reader more information about your data without a great deal of cognitive effort is valuable and should be done. The reader should be aware that many other statisticians oppose the reporting of exact significance levels.)
Analysis of Variance (ANOVA) is a hypothesis testing procedure that tests whether two or more means are significantly different from each other. A statistic, F, is calculated that measures the size of the effects by comparing a ratio of the differences between the means of the groups to the variability within groups. The larger the value of F, the more likely that there are real effects. The obtained F-ratio is compared to a model of F-ratios that would be found given that there were no effects. If the obtained F-ratio is unlikely given the model of no effects, the hypothesis of no effects is rejected and the hypothesis of real effects is accepted. If the model of no effects could explain the results, then the null hypothesis of no effects must be retained. The exact significance level is the probability of finding an F-ratio equal to or larger than the one found in the study given that there were no effects. If the exact significance level is less than alpha, then you decide that the effects are real, otherwise you decide that chance could explain the results.
When there are only two groups, a two-tailed t-test and ANOVA will produce a similar exact significance level and make similar decisions about the reality of effects. Since ANOVA is a more general hypothesis testing procedure, it is preferred over a t-test.