The relative frequency polygon appears as follows:
Cluster analysis classifies a set of observations into two or more mutually exclusive unknown groups based on combinations of interval variables. The purpose of cluster analysis is to discover a system of organizing observations, usually people, into groups. where members of the groups share properties in common. It is cognitively easier for people to predict behavior or properties of people or objects based on group membership, all of whom share similar properties. It is generally cognitively difficult to deal with individuals and predict behavior or properties based on observations of other behaviors or properties.
For example, a person might wish to predict how an animal would respond to an invitation to go for a walk. He or she could be given information about the size and weight of the animal, top speed, average number of hours spent sleeping per day, and so forth and then combine that information into a prediction of behavior. Alternatively, the person could be told that an animal is either a cat or a dog. The latter information allows a much broader range of behaviors to be predicted. The trick in cluster analysis is to collect information and combine it in ways that allow classification into useful groups, such as dog or cat.
Cluster analysis classifies unknown groups while discriminant function analysis classifies known groups. The procedure for doing a discriminant function analysis is well established. There are few options, other than type of output, that need to be specified when doing a discriminant function analysis. Cluster analysis, on the other hand, allows many choices about the nature of the algorithm for combining groups. Each choice may result in a different grouping structure.
It is not the purpose of this chapter to be an extensive presentation of methods of doing a cluster analysis. The purpose of this chapter is to give the student an understanding of how cluster analysis works. The options selected for inclusion in this chapter are designed to be illustrative and easy to compute rather than useful in real work. The interested reader is directed to a more comprehensive work on cluster analysis (Anderberg, 1973).
Cluster analysis has proven to be very useful in marketing. Larson (1992) describes the efforts of a company, Clarita's, to cluster neighborhoods (zip codes) into forty different groups based on census information, such as population density, income, and age. These groups were eventually given names like "Blue Blood Estates," "Shotguns and pickups," and "Bohemian Mix." This classification scheme, call PRIZM for Potential Rating Index for Zip Markets, has proven to be very useful in direct mail advertising, radio station formats, and decisions about where to locate stores.
In cases of one or two measures, a visual inspection of the data using a frequency polygon or scatterplot often provides a clear picture of grouping possibilities. For example, the following is the data from the "Example Assignment" of the cluster analysis homework assignment.
The relative frequency polygon appears as follows:
It is fairly clear from this picture that two subgroups, the first including Julie, John, and Ryan and the second including everyone else except Dave describe the data fairly well. When faced with complex multivariate data, such visualization procedures are not available and computer programs assist in assigning objects to groups. The following text describes the logic involved in cluster analysis algorithms.
A common approach to doing a cluster analysis is to first create a table of relative similarities or differences between all objects and second to use this information to combine the objects into groups. The table of relative similarities is called a proximities matrix. The method of combining objects into groups is called a clustering algorithm. The idea is to combine objects that are similar to one another into separate groups.
Cluster analysis starts with a data matrix, where objects (usually people in the social sciences) are rows and observations are columns. From this beginning, a table is constructed where objects are both rows and columns and the numbers in the table are measures of similarity or differences between the two observations.
For example, given the following data matrix:
| X1 | X2 | X3 | X4 | X5 | |
| O1 | |||||
| O2 | |||||
| O3 | |||||
| O4 |
A proximities matrix would appear as follows:
| O1 | O2 | O3 | O4 | |
| O1 | ||||
| O2 | ||||
| O3 | ||||
| O4 |
The difference between a proximities matrix in cluster analysis and a correlation matrix is that a correlation matrix contains similarities between variables (X1, X2) while the proximities matrix contains similarities between observations (O1, O2).
The researcher has dual problems at this point. The first is a decision about what variables to collect and include in the analysis. Selection of irrelevant measures will not aid in classification. For example, including the number of legs an animal has would not help in differentiating cats and dogs, although it would be very valuable in differentiating between spiders and insects.
The second problem is how to combine multiple measures into a single number, the similarity between the two observations. This is the point where univariate and multivariate cluster analysis separate. Univariate cluster analysis groups are based on a single measure, while multivariate cluster analysis is based on multiple measures.
A simpler version of the problem of how to combine multiple measures into a measure of difference between objects is how to combine a single observation into a measure of difference between objects. Consider the following scores on a test for four students:
| Student | Score |
| Julie | 11 |
| John | 11 |
| Ryan | 13 |
| Bob | 18 |
The proximities matrix for these four students would appear as follows:
| Julie | John | Ryan | Bob | |
| Julie | ||||
| John | ||||
| Ryan | ||||
| Bob |
The entries of this matrix will be described using a capital "D", for distance with a subscript describing which row and column. For example, D34 would describe the entry in row 3, column 4, or in this case, the intersection of Ryan and Bob.
One means of filling in the proximities matrix is to compute the absolute value of the difference between scores. For example, the distance, D34, between Ryan and Bob would be |13-18| or 5. Completing the proximities matrix using the example data would result in the following:
| Julie | John | Ryan | Bob | |
| Julie | 0 | 0 | 2 | 7 |
| John | 0 | 0 | 2 | 7 |
| Ryan | 2 | 2 | 0 | 5 |
| Bob | 7 | 7 | 5 | 0 |
A second means of completing the proximities matrix is to use the squared difference between the two measures. Using the example above, D34, the distance between Ryan and Bob, would be (13-18)2 or 25. This distance measure has the advantage of being consistent with many other statistical measures, such as variance and the least squares criterion, and will be used in the examples that follow. The example proximities matrix using squared differences as the distance measure is presented below.
| Julie | John | Ryan | Bob | |
| Julie | 0 | 0 | 4 | 49 |
| John | 0 | 0 | 4 | 49 |
| Ryan | 4 | 4 | 0 | 25 |
| Bob | 49 | 49 | 25 | 0 |
Note that both example proximities matrices are symmetrical. Symmetrical means that row and column entries can be interchanged or that the numbers are the same on each half of the matrix defined by a diagonal running from top left to bottom right.
Other distance measures have been proposed and are available with statistical packages. For example, SPSS/WIN provides the following options for distance measures.
Some of these options themselves contain options. For example, Minkowski and Customized are really many different possible measures of distance.
When more than one measure is obtained for each observation, then some method of combining the proximities matrices for different measures must be found. Usually the matrices are summed in a combined matrix. For example, given the following scores.
| X1 | X2 | |
| O1 | 25 | 11 |
| O2 | 33 | 11 |
| O3 | 34 | 13 |
| O4 | 35 | 18 |
The two proximities matrices resulting from squared Euclidean distance that result could be summed to produce a combined distance matrix.
| O1 | O2 | O3 | O4 | |
| O1 | 0 | 64 | 81 | 100 |
| O2 | 64 | 0 | 1 | 4 |
| O3 | 81 | 1 | 0 | 1 |
| O4 | 100 | 4 | 1 | 0 |
+
| O1 | O2 | O3 | O4 | |
| O1 | 0 | 0 | 4 | 49 |
| O2 | 0 | 0 | 4 | 49 |
| O3 | 4 | 4 | 0 | 25 |
| O4 | 49 | 49 | 25 | 0 |
| O1 | O2 | O3 | O4 | |
| O1 | 0 | 64 | 85 | 149 |
| O2 | 64 | 0 | 5 | 53 |
| O3 | 85 | 5 | 0 | 26 |
| O4 | 149 | 53 | 26 | 0 |
Note that each corresponding cell is added. With more measures there are more matrices to be added together.
This system works reasonably well if the measures share similar scales. One measure can overwhelm the other if the measures use different scales. Consider the following scores.
| X1 | X2 | |
| O1 | 25 | 11 |
| O2 | 33 | 21 |
| O3 | 34 | 33 |
| O4 | 35 | 48 |
The two proximities matrices resulting from squared Euclidean distance that result could be summed to produce a combined distance matrix.
| O1 | O2 | O3 | O4 | |
| O1 | 0 | 64 | 81 | 100 |
| O2 | 64 | 0 | 1 | 4 |
| O3 | 81 | 1 | 0 | 1 |
| O4 | 100 | 4 | 1 | 0 |
+
| O1 | O2 | O3 | O4 | |
| O1 | 0 | 100 | 484 | 49 |
| O2 | 100 | 0 | 144 | 729 |
| O3 | 484 | 144 | 0 | 225 |
| O4 | 1369 | 729 | 225 | 0 |
| O1 | O2 | O3 | O4 | |
| O1 | 0 | 164 | 485 | 153 |
| O2 | 164 | 0 | 145 | 733 |
| O3 | 565 | 145 | 0 | 226 |
| O4 | 1469 | 733 | 226 | 0 |
It can be seen that the second measure overwhelms the first in the combined matrix.
For this reason the measures are optionally transformed before they are combined. For example, the previous data matrix might be converted to standard scores before computing the separated distance matrices.
| X1 | X2 | Z1 | Z2 | |
| O1 | 25 | 11 | -1.48 | -1.08 |
| O2 | 33 | 21 | .27 | -.45 |
| O3 | 34 | 33 | .49 | .30 |
| O4 | 35 | 48 | .71 | 1.24 |
The two proximities matrices resulting from squared Euclidean distance that result from the standard scores could be summed to produce a combined distance matrix.
| O1 | O2 | O3 | O4 | |
| O1 | 0 | 3.06 | 3.88 | 4.80 |
| O2 | 3.06 | 0 | .05 | .19 |
| O3 | 3.88 | .05 | 0 | .05 |
| O4 | 4.80 | .19 | .05 | 0 |
+
| O1 | O2 | O3 | O4 | |
| O1 | 0 | .40 | 1.90 | 5.38 |
| O2 | .40 | 0 | .56 | 2.86 |
| O3 | 1.9 | .56 | 0 | .88 |
| O4 | 5.38 | 2.86 | .88 | 0 |
| O1 | O2 | O3 | O4 | |
| O1 | 0 | 3.46 | 5.78 | 10.18 |
| O2 | 3.46 | 0 | .61 | 3.05 |
| O3 | 5.78 | .61 | 0 | .93 |
| O4 | 10.18 | 3.05 | .93 | 0 |
The point is that the choice of whether to transform the data and the choice of distance metric can result in vastly different proximities matrices.
After the distances between objects have been found, the next step in the cluster analysis procedure is to divide the objects into groups based on the distances. Again, any number of options are available to do this.
If the number of groups is known beforehand, a "flat" method might be preferable. Using this method, the objects are assigned to a given group at the first step based on some initial criterion. The means for each group are calculated. The next step reshuffles the objects into groups, assigning objects to groups based on the object's similarity to the current mean of that group. The means of the groups are recalculated at the end of this step. This process continues recursively until no objects change groups. This idea is the basis for "k-means cluster analysis" available on SPSS/WIN and other statistical packages. This method works well if the number of groups match the data and the initial solution is reasonably close to the final solution.
Hierarchical clustering methods do not require preset knowledge of the number of groups. Two general methods of hierarchical clustering methods are available: divisive and agglormerative.
The divisive techniques start by assuming a single group, partitioning that group into subgroups, partitioning these subgroups further into subgroups and so on until each object forms its own subgroup. The agglormerative techniques start with each object describing a subgroup, and then combine like subgroups into more inclusive subgroups until only one group remains. The agglormerative techniques will be described further in this chapter, although many of the procedures described would hold for either method.
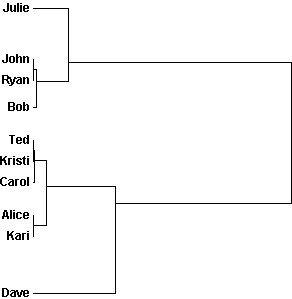
In either case, the results of the application of the clustering technique are best described using a dendogram or binary tree. The objects are represented as nodes in the dendogram and the branches illustrate when the cluster method joins subgroups containing that object. The length of the branch indicates the distance between the subgroups when they are joined. An example dendogram using the example data is presented below:
The interpretation of a dendogram is fairly straightforward. In the above dendogram, for example, Julie, John, and Ryan form a group, Bob, Ted, Kristi, Carol, Alice, and Kari form a second group, and Dave is called a "runt" because he doesn't enter any group until near the end of the procedure.
Different methods exist for computing the distance between subgroups at each step in the clustering algorithm. Again, statistical packages give options for which procedure to use. For example, SPSS/WIN optionally allows the following methods.
The following methods will now be discussed: single linkage or nearest neighbor, complete linkage or furthest neighbor, and average linkage.
Single linkage (nearest neighbor in SPSS/WIN) computes the distance between two subgroups as the minimum distance between any two members of opposite groups. For example, consider the following proximities matrix.
| Julie | John | Ryan | Bob | Ted | Kristi | |
| Julie | 0 | 4 | 36 | 81 | 196 | 225 |
| John | 4 | 0 | 16 | 49 | 144 | 169 |
| Ryan | 36 | 16 | 0 | 9 | 64 | 81 |
| Bob | 81 | 49 | 9 | 0 | 25 | 36 |
| Ted | 196 | 144 | 64 | 25 | 0 | 1 |
| Kristi | 225 | 169 | 81 | 36 | 1 | 0 |
Based on this data, Ted and Kristi would be joined on the first step.
| Julie | John | Ryan | Bob | Ted and Kristi | |
| Julie | 0 | 4 | 36 | 81 | 196 |
| John | 4 | 0 | 16 | 49 | 144 |
| Ryan | 36 | 16 | 0 | 9 | 64 |
| Bob | 81 | 49 | 9 | 0 | 25 |
| Ted and Kristi | 196 | 144 | 64 | 25 | 0 |
Julie and John would be joined on the second step.
| Julie and John | Ryan | Bob | Ted and Kristi | |
| Julie and John | 0 | 16 | 49 | 144 |
| Ryan | 16 | 0 | 9 | 64 |
| Bob | 49 | 9 | 0 | 25 |
| Ted and Kristi | 144 | 64 | 25 | 0 |
Ryan and Bob would be joined on the third step. At that step four would be three groups of two each and the proximities matrix at that point would appear as follows.
| Julie and John | Ryan and Bob | Ted and Kristi | |
| Julie and John | 0 | 16 | 144 |
| Ryan and Bob | 16 | 0 | 25 |
| Ted and Kristi | 144 | 25 | 0 |
Using single linkage, Julie and John would be grouped with Ryan and Bob at the third step. The distance of this linkage would be 16. The last step would join all into a single group with a distance of 25.
The single linkage dendogram of the data generated by "Example Assignment" would appear as follows.
Complete linkage (furthest neighbor in SPSS/WIN) computes the distance between subgroups in each step as the maximum distance between any two members of the different groups. Using the example proximities matrix, complete linkage would join similar members at steps 1, 2, and 3 in the procedure. At step four the proximities matrix for the three groups would appear as follows.
| Julie and John | Ryan and Bob | Ted and Kristi | |
| Julie and John | 0 | 81 | 225 |
| Ryan and Bob | 81 | 0 | 81 |
| Ted and Kristi | 225 | 81 | 0 |
Step four would combine all three subgroups into a single group with a distance of 81.
The dendogram of the "example assignment" data is presented below.
Average linkage (or Centroid Method in SPSS/WIN) computes the distance between subgroups at each step as the average of the distances between the two subgroups.
Using the example proximities matrix, average linkage would join similar members at steps 1, 2, and 3 in the procedure. At step four the proximities matrix for the three groups would appear as follows.
| Julie and John | Ryan and Bob | Ted and Kristi | |
| Julie and John | 0 | 45.5 | 51.5 |
| Ryan and Bob | 45.5 | 0 | 81 |
| Ted and Kristi | 183.5 | 51.5 | 0 |
Thus, Julie and John would be grouped with Ryan and Bob with a distance of 51.5. The final step would join this group with Ted and Kristi with an average distance of 117.5. The dendogram for average linkage in the "Example Assignment" is presented below.
IMG SRC="images/mlt0404.gif" WIDTH='300' HEIGHT='300' />
A program generating a cluster analysis homework assignment permits the student to view a dendogram for single, complete, and average linkage for a random proximities matrix. The student should verify that different dendograms result when different linkage methods are used.
A dendogram that clearly differentiates groups of objects will have small distances in the far branches of the tree and large differences in the near branches. The following example dendogram ideally illustrates two clear groups.
The following dendogram ideally illustrates a clear grouping of three groups.
When the distances on the far branches are large relative to the near branches, then the grouping is not very effective. The following illustrates a dendogram that would be interpreted with great caution.
Dendograms are also useful in discovering "runts", or objects that are joined to a group in the near branches. In the example data "Dave" is clearly a runt, at least in the single linkage dendogram, because he does not join the main group until the last step. Runts are exceptions to the grouping structure.
It has been suggested (Stuetzle, 1995) that some statisticians prefer complete linkage because deceptively cleaner dendograms are often produced. A unimodal distribution will often produce a clean dendogram that might be interpreted as two groups even though no grouping is appropriate. For this reason Stuetzle (1995) recommends that single linkage be used and closely examined for runts.
Performing a cluster analysis using a statistical package is relative easy. An animated illustration of using SPSS/WIN to generate a cluster analysis of the "Example Assignment" data may be viewed by clicking here.
The output from the SPSS/WIN cluster analysis package can be seen by clicking on the appropriate linkage method below.
Single, Complete, and Centroid Method Linkage SPSS/WIN Cluster Output
The student should verify that the dendograms generated using SPSS/WIN are similar to those generated in the homework assignment program.
Cluster analysis methods will always produce a grouping. The groupings produced by cluster analysis may or may not prove useful for classifying objects. If the groupings discriminate between variables not used to do the grouping and those discriminations are useful, then cluster analysis is useful. For example, if grouping zip code areas into fifteen categories based on age, gender, education, and income discriminates between wine drinking behaviors, it would be very useful information if one was interested in expanding a wine store into new areas.
Cluster analysis may be used in conjunction with discriminant function analysis. After multivariate data are collected, observations are grouped using cluster analysis. Discriminant function analysis is then used on the resulting groups to discover the linear structure of either the measures used in the cluster analysis and/or different measures.
Cluster analysis methods are not clearly established. There are many options one may select when doing a cluster analysis using a statistical package. Cluster analysis is thus open to the criticism that a statistician may mine the data trying different methods of computing the proximities matrix and linking groups until he or she "discovers" the structure that he or she originally believed was contained in the data. One wonders why anyone would bother to do a cluster analysis for such a purpose.
The interested reader is directed to a Statsoft web presentation on cluster analysis.