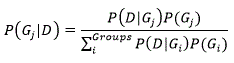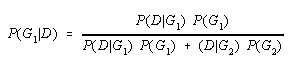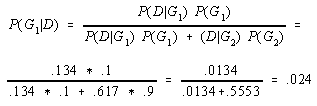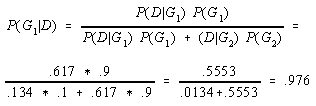The main purpose of a discriminant function analysis is to predict group membership based on a linear combination of the interval variables. The procedure begins with a set of observations where both group membership and the values of the interval variables are known. The end result of the procedure is a model that allows prediction of group membership when only the interval variables are known. A second purpose of discriminant function analysis is an understanding of the data set, as a careful examination of the prediction model that results from the procedure can give insight into the relationship between group membership and the variables used to predict group membership.
Discriminant function analysis is used to predict group membership based on a linear combination of interval predictor variables. The procedure begins with a set of observations where both group membership and the values of the predictor variables are known with the end result being a linear combination of the interval variables that allows prediction of group membership. The way in which the interval variables combine allows a greater understanding and simplification of a multivariate data set. Discriminant analysis, based on matrix theory, is an established technology that has the advantage of a clearly defined decision-making process. Machine learning techniques such as neural networks may alternatively be used for predicting group membership from similar data, often with more accurate predictions, as long as the statistician is willing to accept decision-making without much insight into the process.
For example, a researcher might have a large data set of information from a high school about their former students. Each student belongs to a single group: (1) did not graduate from high school (2) graduated from high school or obtained a GED (3) attended. The researcher wishes to predict student outcome group using interval predictor variables such as: grade point average, attendance, degree of participation in various extra-curricular activities (band, athletics, etc.), weekly amount of screen time, and parental educational level. Given this complex multivariate data set and the discriminant function analysis procedure, the researcher can find a subset of variables that in a linear combination allows prediction of group membership. As a bonus, the relative importance of each variable in this subset is part of the output. Often researchers are satisfied with this understanding of the data set and stop at this point.
Discriminant function analysis is a sibling to multivariate analysis of variance (MANOVA) as both share the same canonical analysis parent. Where MANOVA received the classical hypothesis testing gene, discriminant function analysis often contains the Bayesian probability gene, but in many other respects they are almost identical.
This entry will attempt to explain the procedure by breaking it down into its component parts and then assembling them into a whole. The two main component parts in discriminant function analysis are implicit in the title: discriminating between groups and functional analysis. Because knowledge of how to discriminate between groups is necessary for an understanding of the later functional analysis, it will be presented first.
For example, a graduate admissions committee might divide a set of past graduate students into two groups: students who finished the program in five years or less and those who did not. Discriminant function analysis could be used to predict successful completion of the graduate program based on GRE score and undergraduate grade point average. Examination of the prediction model might provide insights into how each predictor individually and in combination predicted completion or non-completion of a graduate program.
Another example might predict whether patients recovered from a coma or not based on combinations of demographic and treatment variables. The predictor variables might include age, sex, general health, time between incident and arrival at hospital, various interventions, etc. In this case the creation of the prediction model would allow a medical practitioner to assess the chance of recovery based on observed variables. The medical practitioner might be using the results of a discriminant function analysis when telling a patient that she has an 80% chance of recovery, even though the medical practitioner may have obtained this value by entering numbers into a computer program and have little concept of how it was computed. The prediction model might also give insight into how the variables interact in predicting recovery.
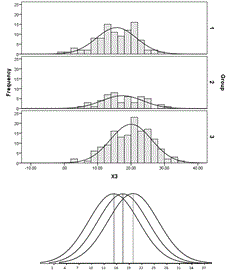
The simplest case of discriminant function analysis is the prediction of group membership based on a single variable. An example might be the prediction of successful completion of high school based on the attendance record alone. For the rest of this section, the example will use three simulated groups with Ns equal to 100, 50, and 150, respectively.
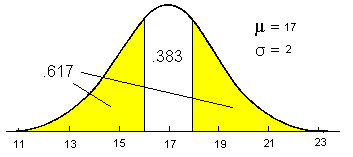
In the example (Figures 1), histograms are drawn separately for each of the three groups. Secondly, overlapping normal curve models are shown where the normal curve parameters mu and sigma are estimated by the mean and standard deviation of the three groups. An ANOVA analysis shows that the three means are statistically different from each other, but only limited discrimination between groups is possible
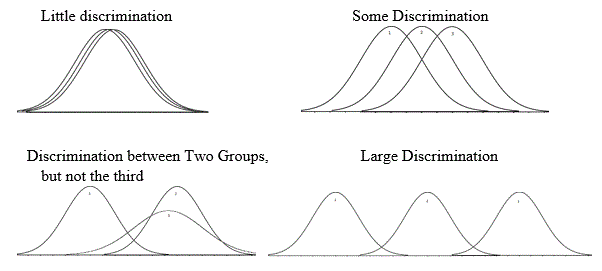
Figure 2 shows various possibilities for overlapping group probability models, from little or no discrimination to almost perfect discrimination between groups. Note that the greater the difference between means relative to the within group variability, the better the discrimination between groups.
Given that means and standard deviations can be calculated for each group, different classification schemes can be devised to classify scores based on a single variable. One possibility is to simply measure the distance of a particular score from each of the group means and select the group that has the smallest distance. (In discriminant function analysis, group means are called centroids.) This system has the advantage that no distributional assumptions are necessary.
While not absolutely necessary to perform a discriminant function analysis, Bayes Theorem offers a distinct improvement over distance measures. Bayes Theorem modifies existing probabilities, called prior probabilities, into posterior probabilities using evidence based on the collected data. In the case of discriminant function analysis, prior probabilities are the likelihood of belonging to a particular group before the interval variables are known and are generally considered to be subjective probability estimates. Prior probabilities will be symbolized as P(G). For example, P(G1) is the prior probability of belonging to group 1. In discriminant function analysis programs (e.g. SPSS), the default option is to set all prior probabilities as equally likely. For example, if there were three groups, each of the three prior probabilities would be set to .33333…. Optionally, the prior probabilities can be set to the relative frequency of each group. In the example data with N’s of 100, 50, and 150, the prior probabilities would be set to .333…, .16666…, and .75, respectively. Since prior probabilities are subjective, it would also be possible to set them based on cost of misclassification. For example, if misclassification as group 1 membership is costly, the prior probability might be set to .10, rather than .333….
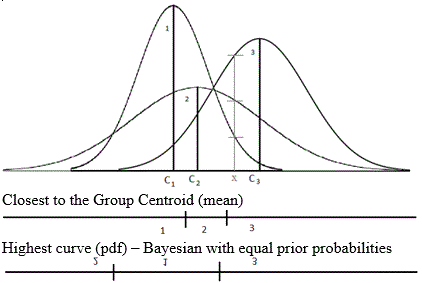
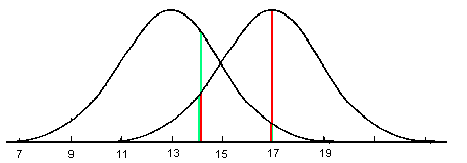
The probability models of the predictor variables for each group can be used to provide the conditional probability estimates of a score (D) given membership in a particular group, P(D|G). Using the pdf of the probability model, the height of the curve at the data point can be used as an estimate of this probability. Figure 3 illustrates this concept at the data point x, where P(D=x|G1) #60 P(D=x|G2) #60 P(D=x|G3).
Bayes Theorem provides a means to transform prior probabilities into posterior probabilities given the conditional probabilities P(D|G). Posterior probabilities are the probability of belonging to a group given the prior and conditional probabilities. In the case of discriminant function analysis, prior probabilities P(G) are transformed into posterior probabilities of group membership given a particular score P(G|D). The formula for computing P(G|D) using Bayes Theorem is as follows:
The Bayesian classification system works by computing the posterior probability at a given data point for each group and then selecting the group with the largest posterior probability. If equal prior probabilities are used, then P(Gi) is a constant for all groups and can be cancelled from the formula. Since the denominator is the same for all groups, the classification system will select the group with the largest P(D|G). In the case of the normal curve examples of conditional distributions presented in Figure 3, at any given point on the x-axis the selected group would correspond to the group with the highest curve. This is reflected on the last territorial map on the figure. Note how different it is from the classification system based on distances from each mean. If unequal prior probabilities are used, then the posterior probabilities are weighted by the prior probabilities and the territorial maps will necessarily change.
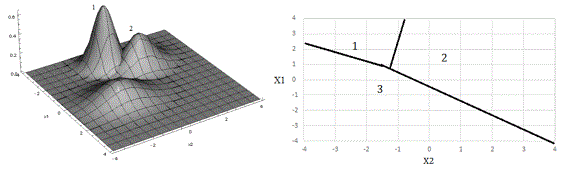
In some cases, especially with multiple groups and complex multivariate data, discrimination between groups along a single dimension is not feasible and multiple dimensions must be used to insure reasonably correct classification results. A visual representation of a fairly simple situation with two dimensions and three groups is presented in Figure 4. Note that better classification results can be obtained using two dimensions than any single dimension.
Conceptually, the classification methods are fairly straightforward extensions of the classification systems along a single dimension, although visual representations become much more problematic, especially in three or more dimensions.
Various methods of computing distances from the group centroids can be used and the minimum distance can be used as a classification system. The advantage to using distance measures is that no distributional assumptions are necessary.
When using a Bayesian classification system, distributional assumptions are necessary. One common distributional assumption is a multivariate normal distribution. The requirements for a multivariate normal distribution are much more stringent and complex than for a univariate normal distribution and therefore harder to meet. For example, both X1 and X2 could be normally distributed, but the combination might not be a bi-variate normal distribution. The multivariate normal assumption becomes even more problematic with many more variables. If the distributional assumptions are acceptable, then the Bayesian classification system proceeds in a manner like discriminating between groups with a single variable. The advantage to using a Bayesian classification system is that posterior probabilities of belonging to each group are available.
The simplest case of discriminant function analysis is the prediction of dichotomous group membership based on a single variable. An example of the simplest case is the prediction of successful completion of a graduate program based on the GRE verbal score. In this case, since the prediction model includes only a single variable, it gives little insight into how variables interact with each other in prediction. Thus prediction of group membership will be the major focus of the next section of this chapter.
With respect to the data file and purpose of analysis, this simplest case is identical to the case of linear regression with dichotomous dependent variables. As discussed previously, data of this type may be represented in any number of different forms: scatter plots, tables of means and standard deviations, and overlapping frequency polygons. Because overlapping frequency polygons have such an intuitive appeal, they will be used to describe how discriminant function analysis works.
A single interval variable might discriminate between groups in an almost perfect fashion, not at all, or somewhere in between. For example, if one wished to differentiate adult males and females, one could collect information on how many bras the person owned, score on the last statistics test, and height. In the case of the number of bras, the discrimination would be very good, but not perfect (some women don't own any bras, some men do). In the case of the score on the last statistics test, little discrimination would be possible because males and females generally score about the same. In the case of height, some discrimination between adult males and females would be possible, but it would be far from perfect.
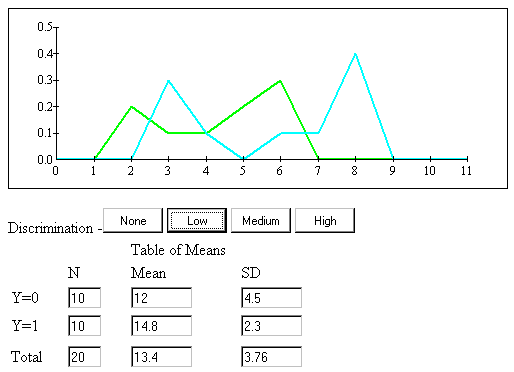
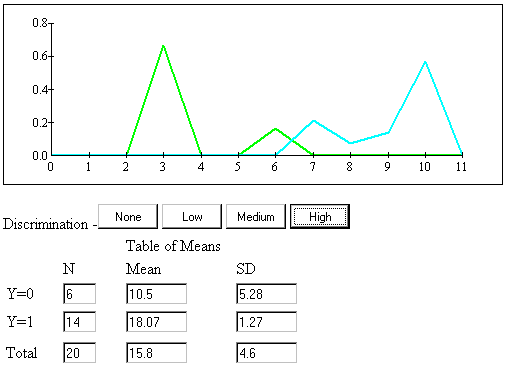
In general, the larger the difference between the means of the two groups relative to the within groups variability, the better the discrimination between the groups. The following program allows the student to explore data sets with different degrees of discrimination ability.
The figure below shows the results of the program when the discrimination is set to low.
The next figure shows the results when the discrimination is set to high.
Note that the two frequency polygons overlap a great deal when there is little or no discriminability between groups and hardly at all when there is high discriminability. In the same vein, the means are fairly similar relative to their standard deviations in the low discriminability condition and different in the high discriminability condition.
Discriminant function analysis is based on modeling the interval variable for each group with a normal curve. The mean of each group is used an estimate of mu for that group. Sigma for each group can be estimated by using weighted mean of the within group variances or using the standard deviation of that group. In the case of the weighted mean the variances are weighted by sample size and can be calculated either as the denominator for a nested t-test or as the square root of the Mean Squares Within Groups in an ANOVA, providing identical estimates. When using the weighted mean of the variances, one must assume that the generating function for each group produces numbers that in the long run have the same variability.
In the simple case of dichotomous groups and a single predictor variable, it really does not make a great deal of difference in the complexity of the model if the variability of each groups is assumed to be equal or not. This is not true, however, when more groups and more predictor variables are added to the model. For that reason, the assumption of equality of within group variance is almost universal in discriminant function analysis.
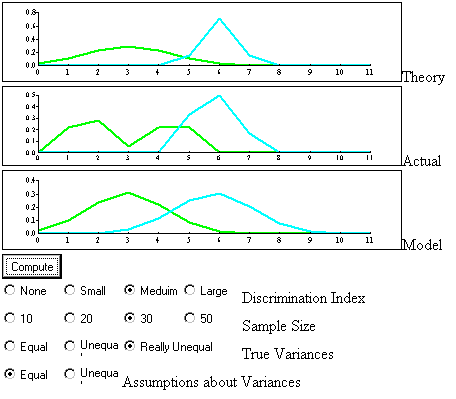
The following program allows the student to explore the relationship between different generating functions (poor, medium, or good discrimination; equal or unequal variances), sample size, and resulting model based on the sample. The student should verify that larger sample sizes provide resulting models that are more similar to the generating model. The student should also explore the effect of violations of the equality of variance assumptions on the resulting model.
The normal curve models of the predictor variables for each group and can be used to provide probability estimates of a particular score given membership in a particular group. In discriminant function analysis, the area in the tails under a normal curve model for a given group between points equally distant from mu is the probability of either point given that group. This probability is symbolized as P(D/G) on SPSS output.
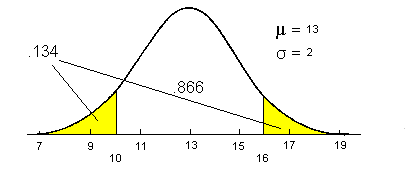
For example, suppose that the normal curve model for a given group has a value of 13 for mu and 2 for sigma. The probability of a score of 16 would be the area in the tails of this normal curve between 10 and 16. The value of 10 was selected as the low score because 16 is three units above the mean (16-13 = 3) and 10 is three sigma units below the mean (13-3 = 10). This is all much easier visualized than stated.
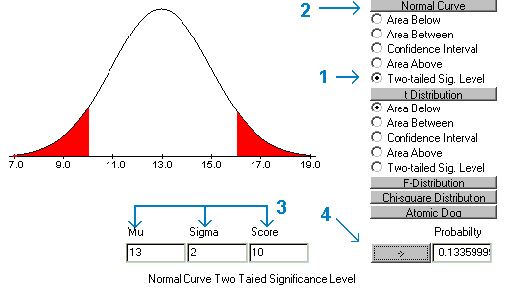
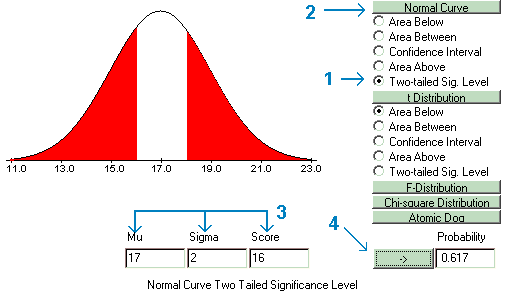
This area could be found using the probability calculator by finding the two-tailed significance level for a score of 10 under a normal curve with mu equal to 13 and sigma equal to 2.
A score of 10 would have the same probability as a score of 16 because it is an equal distance from mu.
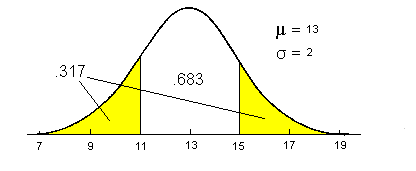
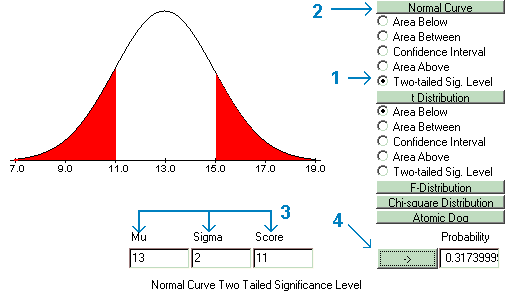
In a similar manner the probability of membership in this group given a score of 11 could be found as the area in the tails of a normal curve with mu=13 and sigma=2 between a score of 11 and 15.
If the second group had a mean of 17 and the same value for sigma (2), then the probability of a score of 16 would be equal to .617 and could be found and visualized as follows:
Computation of low and high scores for large numbers of points could be tedious and is best left to computers. A program to compute P(D/G) for two groups requires that the user enter the means for the two groups, the value for Mean Square Within Groups (from the ANOVA source table), and the score value. Using the preceding examples with group means of 13 and 17, a Mean Square Within of 4 (22), and a score of 16 would generate the following results:
Interpretation of P(G/D) is the likelihood of membership in a group given a particular score. In some cases involving extreme scores, the likelihood of belonging to either group will be small. In other cases involving scores that fall almost equidistant from either mean, the likelihood of belonging to either group will be similar. Rather than simply observing predicted group membership, the student is advised to check probabilities of membership in all groups.
Probability Calculator
Prior probabilities are the likelihood of belonging to a particular group given no information about the person is available. In the classical testing literature prior probabilities are called base rates. Prior probabilities influence our decisions about group membership. Prior probabilities will be symbolized as P(G) . For example, P(G1) is the prior probability of a score belonging to group 1.
Consider the case of prediction of completion of graduate school using GRE verbal scores. Suppose that 99% of the students who started the graduate program successfully completed the program (it was a really easy program). Even if a student scored considerably lower than the mean of the successful group, program completion would most likely be predicted because almost everyone finishes. Likewise, in a graduate program where less than 10% of beginning students complete the program, the likelihood of completion will be fairly low no matter how high the GRE verbal score.
As discussed in the chapter on probabilities in the introductory text, Bayes Theorem provides a means to transform prior probabilities into posterior probabilities. In the case of discriminant function analysis, prior probabilities P(G) are transformed into the posterior probabilities of group membership given a particular score P(G/D) using information about the discriminating variables. The formula for computing P(G/D) using Bayes Theorem is as follows:
For example, if the prior probability of membership in group 1 was .10, P(G1)=.10, and the probability of a score of X=16 given membership in group 1 was .134, P(D=16/G1)=.134, then the posterior probability, P(G1/D=16, would be .024. Computation of this result can be seen below.
In a similar manner, if the prior probability of membership in group 2 was .90, P(G2)=.90, and the probability of a score of X=16, given membership in group 2 was .617, P(D=16/G2)=.617, then the posterior probability, P(G2/D=16 would be .976. Computation of this result can be seen below.
These posterior probabilities can be compared with those where the prior probabilities of group membership is equal to understand the effect of setting different prior probabilities on the values of the posterior probabilities
The sum of the posterior probabilities for all groups will necessarily be one. In the previous example P(G1/D=16) + P(G2/D=16) = .178 + .822 = 1.0. Predicted group membership involves comparing posterior probabilities and selecting the group that has the largest value. It is possible for a score to be unlikely to belong to either group, yet have a high posterior probability of belonging to one group or the other, as can be seen below.
Posterior probabilities are included in the program to compute probabilities in discrimination function analysis. Note that the default value for prior probabilities is .5 for each group. The SPSS discriminant function analysis program also defaults to equally likely priors and allows the user to optionally supply different prior probabilities for group membership.
The effect of setting different prior probabilities can be seen in the following examples.
The following animated illustration has been prepared to show the steps necessary to run a discriminant function analysis using SPSS. The data file includes a dichotomous dependent variable labeled "Y" and an interval independent variable labeled "X". Some options have been selected to provide additional output.
Given the following raw data.
A discriminant function analysis was done using SPSS. The output from the discriminant function analysis program of SPSS is not easy to read, nor is it particularly informative for the case of a single dichotomous dependent variable. One can only hope that future versions of this program will include improved output for this program. The output has been cut up and rearranged. It is highly recommended that the student have a copy of the complete output from this analysis in addition to this text in order to locate the portion of the output that is being discussed.
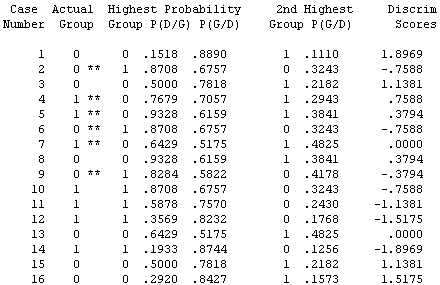
Classification probabilities for each score must be optionally requested and are presented in the following table. SPSS does not provide P(D/G) for the 2nd highest group.
A rather crude frequency polygon is also provided given that it is optionally requested.
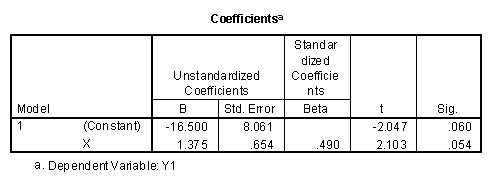
The unstandardized canonical discriminant function coefficients are the regression weights for prediction of a dichotomous dependent variable. The following compares this portion of the output of the discriminant functional analysis program
with a similar portion of the output from the regression package where the Y variable has been recoded to values of 7 and -9.
The regression weights are a multiple of each other. For example the constant terms in the two equations are related by the constant value of -16.50/-4.55=3.63. Likewise, the slopes of the two equations are related by the same constant value of 1.375/.379 =3.63. A proper rescaling of the Y variable would result in equivalent equations (Flury and Riedwyl, 1988).
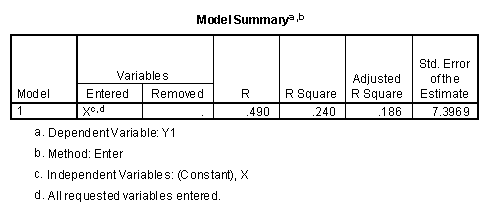
Since there is only one independent variable in the prediction equation, the canonical correlation coefficient is equal to the correlation coefficient (.49). Note also that the significance level of Wilks' Lamba (.054) is the same as the significance level for the t-test for the b1 value in the table above. The following is from the discriminant function analysis program.
The following is from the regression program.
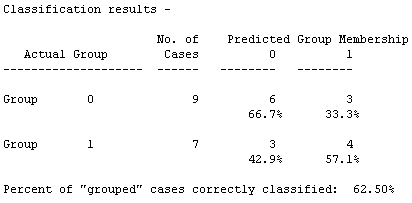
A table of actual and predicted group membership may also be optionally requested.
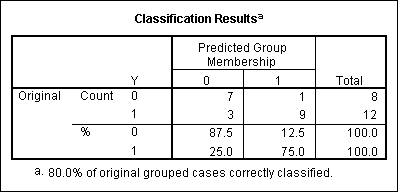
It can be seen that the procedure is slightly more accurate (66.7%) in predicting group membership in group 0 than in group 2 (57.1%).
For reasons that I have not been able to fully comprehend, SPSS computes probability of group membership as the relative height of the normal curve at a given point (Tatsuoka, 1971). The following figure gives an example of the calculation of probabilities based on the height of the normal curve.
The following program will generate probabilities for discriminant function analysis based on the relative height of the normal curve at any point. This program should be used to match the probabilities generated using SPSS.
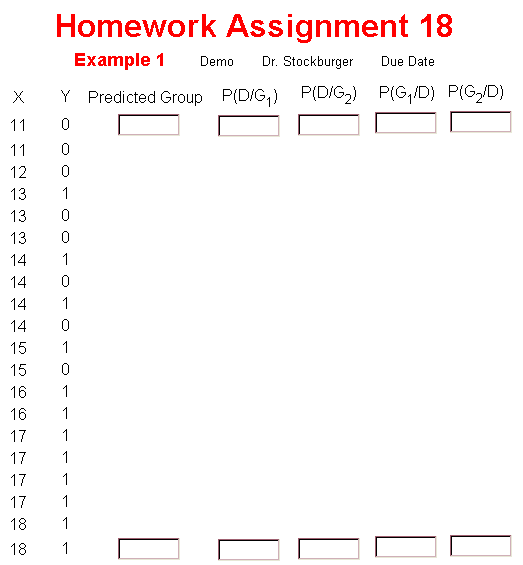
This section will guide the reader through the discriminant function analysis homework assignment. It will demonstrate the use of both the Discriminant Function Probabilities program and the SPSS discriminant function analysis option. The exercise consists of two parts: the raw data and classification section appearing below
and a statistics section, shown as follows.
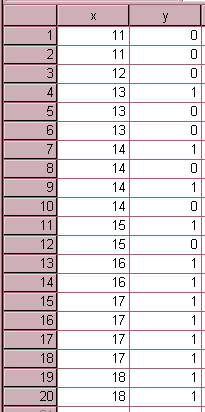
The first step is the creation of a data file in SPSS. The data editor for the example data appears below.
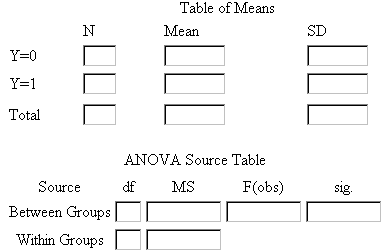
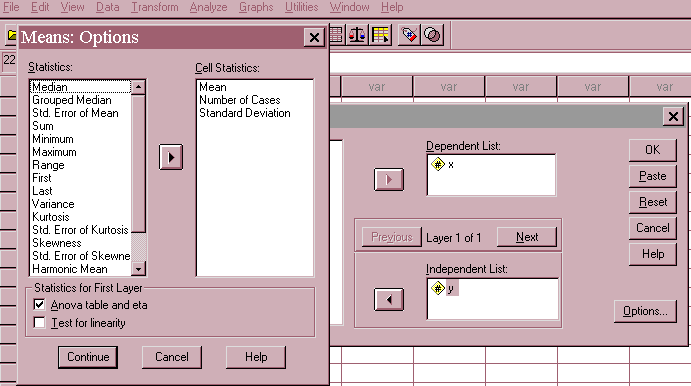
After creating the data file, the first step in the analysis procedure is finding the means and variances of the two groups and performing an ANOVA on the results. This can be done with a statistical calculator or using the SPSS Analyze/Compare Means/Means command. The screen snapshot below shows the interface for the Means command and the example data. Note that an "ANOVA Table and Eta" has been optionally requested.
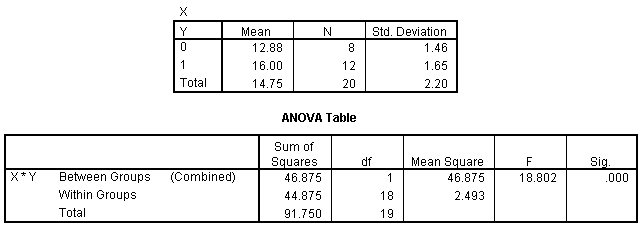
The output resulting from running this command is shown below.
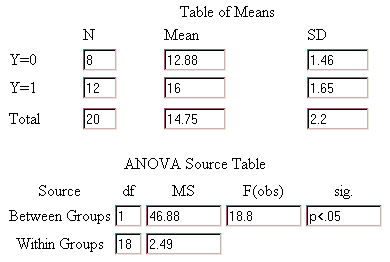
This output can be copied directly into the statistical section of the homework assignment and is necessary before the classification section can be completed. The completed statistical section is shown below.
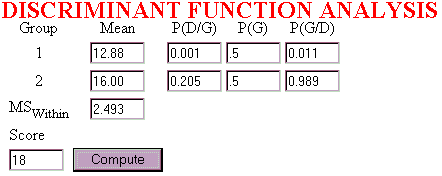
At this point the normal curve option of the Probability Calculator could be used to find P(D/G) for each score for both groups and then Bayes theorem could be used to find P(G/D) for each group. Far easier is the use of the Discriminant Function Probabilities program supplied with this text. The probabilities for this assignment are based on a direct application of Bayes theorem and not the SPSS probabilities. Do not choose the SPSS probabilities option. After calling the program, enter the two means and the mean square within found in the previous step into the appropriate text boxes in the program interface. This needs to be done only once. Following this, enter each different score into the Score text box and click on the Compute button. The results for the first score of 11 should appear as follows.
The results of the final score of 18 appear as follows.
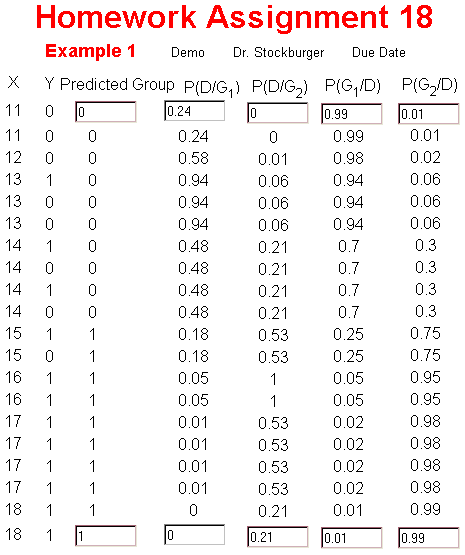
The probabilities found using the Discriminant Function Probabilities can be entered directly on the assignment. The predicted group will be found by comparing the P(G/D) for both groups. The group with the higher P(G/D) is the predicted group. At some point in the data, the predicted group will switch from group 0 to group 1. In the example data below, a score of 14 is the cutoff for predicted membership in group 0.
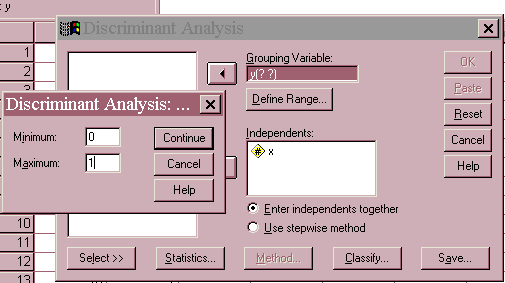
The results could be submitted for grading at this point, but a few minutes spent submitting the data to the Discriminant Function Analysis program in SPSS will allow you to verify your results and better understand the SPSS output. Use the Analyze/Classify/Discriminant Analysis command with the example data. The X variable is selected as the independent variable and Y is the grouping variable. You must tell this SPSS command how you coded your groups by clicking on the Define Range button. In this case the groups were coded as 0 and 1, so these values are entered in the corresponding text boxes. The interface and example data analysis is shown below.
You need to optionally request some additional output. Click on the Classify button and select casewise results, summary table, and territorial map as options in the resulting screen. The selection of the options for this command is illustrated below.
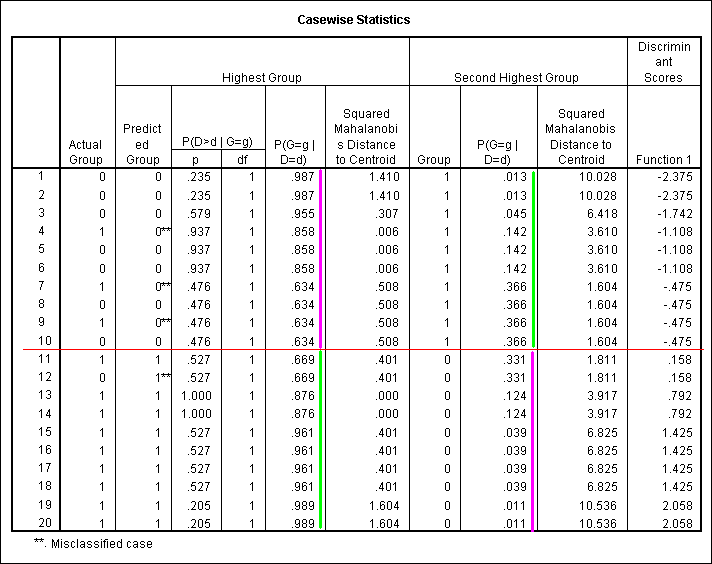
The optional casewise results output from the SPSS discriminant function analysis program is presented below. Note that the P(D/G) matches the P(D/G) probabilities on the assignment except that after the tenth score (the red line on the figure) the results refer to different groups. The P(G/D) is presented for both groups in the output, but it will differ from that on the assignment because it is computed using a different method, as discussed earlier in this text.
The results of the optional summary classification table is presented below. Note that the 80% of the total sample was correctly classified.
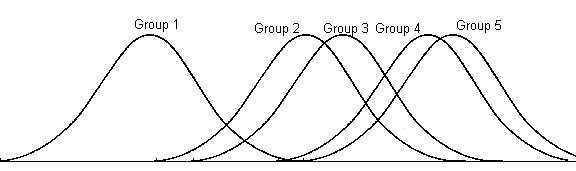
The extension of discriminant function analysis to situations where there are three or more groups is straightforward. Probabilities of the observed score given group membership are computed in a manner similar to the case of dichotomous groups. The only difference is that there are more probabilities to compute. The following illustrates overlapping probability models for five groups.
In this case some groups could be discriminated more easily than others. For example, group 1 differs from the others, while groups 2 and 3 could be discriminated from groups 4 and 5. It would be difficult to discriminate membership in group 2 from group 3 using this single variable.
A real-life application of discriminant function analysis will now be presented to illustrate the potential usefulness of this technique.
In the criminal justice system in the United States defense attorneys often attempt to have their clients declared incompetent to stand trial. Being incompetent to stand trial basically means the person being accused has little knowledge of the criminal justice procedure and is incapable of assisting in his or her own defense. Being declared incompetent to stand trial does not absolve someone of criminal activity, but it can often delay the trial. Because the longer a case takes to go to trial, the more likely witnesses are to disappear, the less the publicity around the crime, or the less likely the government is to prosecute, criminals sometimes wish to be found incompetent to stand trial when if fact they are not. To achieve this end they malinger, or fake, their answers on psychological tests. One of the functions of Psychologists in the prison system in the United States is to testify as to the competence to stand trial of various accused persons. They are asked to give an opinion as to whether the accused is truly incompetent or malingering.
In the example study ????(2001), one hundred and twenty prisoners completed a psychological inventory called the MMPI, or Minnesota Multiphasic Personality Inventory. This inventory consists of 571 true/false questions such as "I often bite my nails." Forty of prisoners were told to malinger and pretend they were incompetent to stand trial, forty were truly incompetent, and forty were competent, but psychiatric, patients. The purpose of the study was to create a new scale that could differentiate between the three groups to assist the Psychologist in testifying as to the true competence to stand trial of the person being accused.
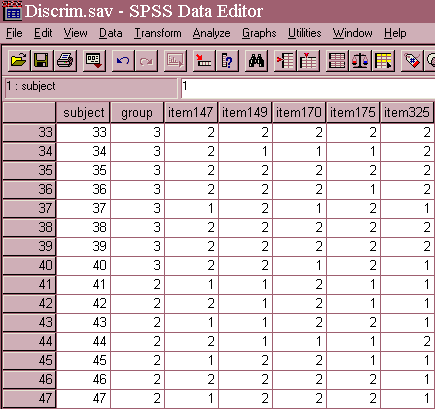
For demonstration purposes, the data set has been reduced to five items on the MMPI. These items have been coded as 1=false and 2=true in the example data set. A portion of the data editor file is shown below.
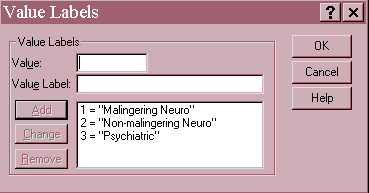
The Group variable is coded with the following value labels.
Using the example data, a discriminant function analysis was performed using the SPSS Analyze/Classify/Discriminant Function command sequence. The five items were used as independent variables and the group variable was selected as the grouping variable. A minimum value of 1 and a maximum value of 3 were selected as the range of the grouping variable. Optional classification results and plots were requested.
The procedure will return more than one discriminant function when there are more than two groups and at least two independent variables. The number of possible discriminant functions can be computed by finding the smaller of one minus the number of groups or the number of independent variables. In this case one minus the number of groups is two and the number of independent variables is five, so there can be two discriminant functions.
Not all the discriminant functions will be equally useful in discriminating between groups and the next step in the analysis is often to decide how many to use. This decision is aided by the following table of eigenvalues. The term eigenvalue will be discussed in detail in a later chapter. For the purposes of this discussion, examination of the relative percent of variance accounted for by each discriminate function will provide useful information. Here it can be seen that the first discriminant function accounts for about 76 percent of the variance, or about three times the percent of variance of the second discriminant function, or 24 percent. Although both functions will be examined in the following discussion, only the first is likely to discriminate between the groups with any accuracy.
The next table of interest in the discriminant function output of SPSS is the table of standardized discriminate function coefficients presented below.
These coefficients allow the computation of new variables that can be used to discriminate between groups in the same manner as the single variable in the earlier presentation. Because the new variable is standardized, the first step in computation is to convert all the dependent variables to standard scores. This can be easily accomplished by the Analyze/Descriptives/Descriptive Statistics command and selecting the save standard scores option.
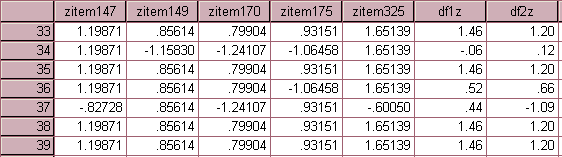
The second step is the multiplication of the standardized canonical discriminate function coefficients times each of the standard scores and then summing the results. For example, finding the first discriminate function for subject 33 could be done as follows:
(.716*1.198) + (.433*.856) + (-.147*.799) + (.475*.932) + (-.054*.165) = 1.46
The computation is done using the Compute command in SPSS with two new variables added to the data file named df1z and df2z. The resulting data file is presented in the following figure.
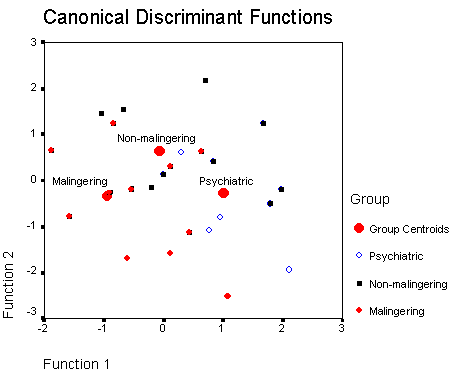
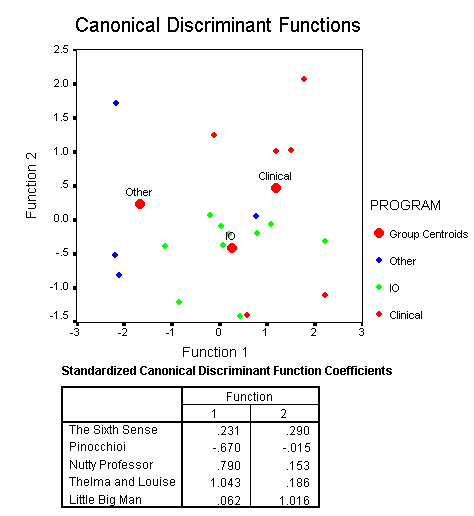
The resulting discriminate function can be plotted in a scatter plot as an option in the SPSS discriminate function analysis program to give a visual representation of the results. In the following the large red dots indicate the centroids, or means, of each of the three groups on the computed discriminate function variables. Group membership is indicated by the use of different markers and colors for each subject. The scatter plot is presented below.
By projecting the points onto the x-axis you can get a pretty good idea of how the first discriminate function works to discriminate between groups. The malingering groups scores the lowest, the non-malingering group is in the middle, and the psychiatric group scores the highest on this variable.
In a similar manner, the discrimination of the second discriminate function can be seen by projecting the points onto the y-axis. In this function the non-malingering group can be distinguished from the malingering and psychiatric groups, but the latter two groups may not be differentiated. The centroids of the latter two groups project to pretty much the same value on the y-axis.
Each of the computed discriminate function can be used individually or in combination to compute the P(D/G) for each subject and each group. The discriminate function probability calculator cannot be used because it was designed for use with only two groups, but in concept the methods are identical. After the values of P(D/G) are found, the values of P(G/D) may be found using Bayes theorem. Because SPSS finds these values automatically as part of the output, there is little reason to do so by hand.
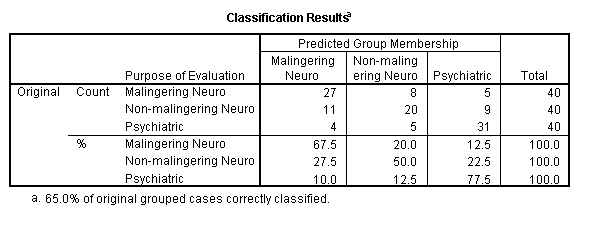
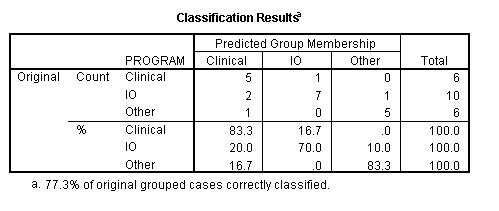
The summary table of classification by the original discriminant functions is part of the optional SPSS output of the discriminant function program and is presented below for the example data.
The overall correct classification rate was 65 percent. Psychiatric patients were most likely to be correctly classified (77.5%), while non-malingering patients were least likely to be correctly classified (50%). Depending upon the cost of each type of misclassification error, the statistician might want to adjust the classification cutoff points.
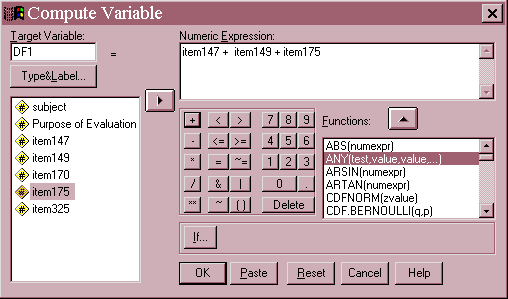
Implementing standardized scores and standardized canonical discriminant function weights can be cumbersome. Most often the statistician would use the results of the discriminant function analysis to construct a new scale, generally ignoring item weights. For example, the first discriminant function, has three items with weights with a fairly high absolute value, items 147 (.716), 149 (.433), and 175 (.475). The items were first recoded to a value of 0=false and 1=true and then added together using the compute statement in the following illustration.
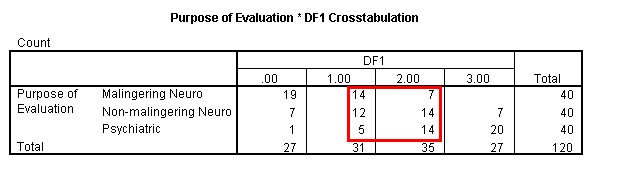
The resulting value, called df1 for discriminant function one, is a number between zero and three corresponding to the number of times true was selected in these three items. Creating a summary classification table using the SPSS Analyze/Descriptives/Crosstabs resulted in the following table.
It can be seen in the contingency table that the scores of 1 and 2 on the df1 variable could be combined into a prediction of non-malingering with a slight loss of information (the red box defines the new classification). Recoding the df1 variable into predicted group membership using discriminant function one resulted in the following summary classification table.
An overall correct classification rate of 54.4% is found. You can see that this classification system was biased in favor of a classification of non-malingering, with 66 out of 120 classified in this category. This bias resulted in 26 out of 40, or 65% of the non-malingering group being correctly classified.
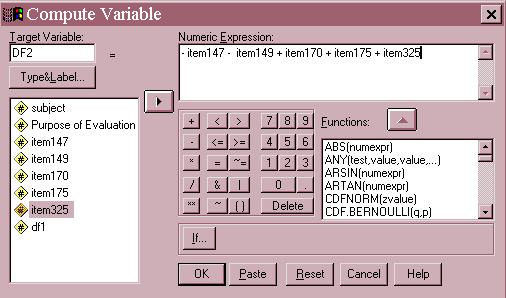
A similar recoding and computing of the second discriminate function could be done, but the likelihood of success is small based on the relatively small eigenvalue for this function. Based on the sign and absolute values of the standardized canonical discriminant function coefficients, this variable (df2 for discriminant function two) will be constructed by subtracting items 145 and 147 and adding items 170, 175, and 325. Because these variables have been recoded to value of 0=false and 1=true, df2 can take on values between -1 and 3. In general, the higher the value of this variable, the more likely the patient belongs to the non-malingering group. The compute command for this variable is illustrated below.
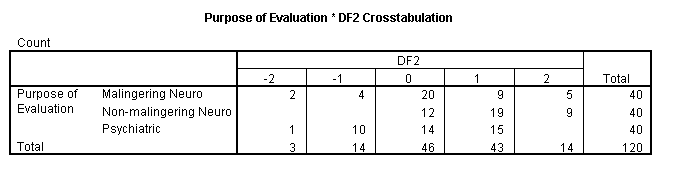
A contingency table of group membership and computed discriminant function two is shown below.
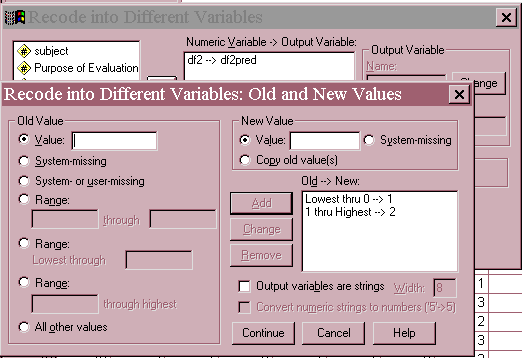
Examination of this contingency table indicates that this variable might be useful in discriminating between the non-malingering and other groups. A cutoff score of 1 was selected to be included in the non-malingering group. In other words, if the patient made a score of -2, -1, or 0, he or she would be included in the malingering or psychiatric group, otherwise, a score of 1, 2, or 3 would place the patient in the non-malingering group. The recode command that transforms the variable into predicted group membership is shown below.
The resulting classification summary table is presented below.
Of the 40 malingering subjects, 26 were classified as malingering and 14 as non-malingering. Of the 40 non-malingering subjects, 28 were correctly classified as non-malingering and 12 as malingering. Of the 40 psychiatric patients, 25 were classified as malingering and 15 as non-malingering. A correct classification ratio of 67.5% was found for classifying the malingering and non-malingering groups. This discriminate function does not discriminate between the malingering and psychiatric groups, however, and is of limited use.
Discriminate function analysis is a useful statistical technique for classifying units, usually individuals in Psychology, into known groups based on linear combinations of interval score variables. The procedure works by solving for weights, which when multiplied times the variables and summed, provides maximum discrimination between groups. The weighted combination of scores is called a linear discriminate function.
The linear discriminate functions can then be used to compute the probability of the data given each group, P(D/G), for each unit. A normal curve with assumptions about equality of variances is usually used to model the data to compute these probabilities. In more complex analyses involving multiple groups and multiple independent variables (scores), more stringent assumptions involving multivariate normal distributions are usually made.
After the probability of the data given each group is estimated for each unit and the prior probabilities are set, Bayes theorem may be used to estimate the probability of each group given the data, P(G/D), for each unit. The unit is predicted to belong in the group with the highest P(G/D). Goodness of fit of the model is usually assessed by examination of the overall percent of correct classifications of units into groups.
Discriminant function analysis has been around since its origin with two defined groups by R. A. Fisher in 1936. It was later extended by others to include more than two groups. Because of the computational difficulty of the analysis, it was not extensively used until computers became widely available. It has the advantage of describing a complex decision process with a few parameters and producing results that can be interpreted.
Discriminant function analysis’s linear models are also its main disadvantage, as many relationships in the real world are not linear. The availability of programs that can be trained to use multiple “if-then” statements or neural networks that learn complex relationships with large data sets and estimation of thousands of parameters have eclipsed the use of linear models. The accuracy of these types of programs is generally greater than linear models, but comes at a cost to the researcher of not understanding the “why” of the decisions.
A second major disadvantage of discriminant function analysis is the reliance on the assumption of multivariate normal distributions for classification. While classification decisions can be made without reference to this assumption, when it is made, it is almost certain to be incorrect. How robust the system is with respect to this assumption can be checked with use of two data sets, one for training and one for testing.
Discriminant function analysis offers a powerful tool to discriminate between groups based on creating new variables, called discriminant functions, using linear models of existing interval variables. Measures of accuracy of prediction along with the manner in which the variables combine provide the statistician with a means of understanding multivariate data.