Does the coffee I drink almost every morning really make me more alert. If all the students drank a cup of coffee before class, would the time spent sleeping in class decrease? These questions may be answered using experimental methodology and hypothesis testing procedures.
The last part of the text is concerned with Hypothesis Testing, or procedures to make rational decisions about the reality of effects. The purpose of hypothesis testing is perhaps best illustrated by an example.
To test the effect of caffeine on alertness in people, one experimental design would divide the classroom students into two groups; one group receiving coffee with caffeine, the other coffee without caffeine. The second group gets coffee without caffeine rather than nothing to drink because the effect of caffeine is the effect of interest, rather than the effect of ingesting liquids. The number of minutes that students sleep during that class would be recorded.
Suppose the group, which got coffee with caffeine, sleeps less on the average than the group which drank coffee without caffeine. On the basis of this evidence, the researcher argues that caffeine had the predicted effect.
A statistician, learning of the study, argues that such a conclusion is not warranted without performing a hypothesis test. The reasoning for this argument goes as follows: Suppose that caffeine really had no effect. Isn't it possible that the difference between the average alertness of the two groups was due to chance? That is, the individuals who belonged to the caffeine group had gotten a better night's sleep, were more interested in the class, etc., than the no caffeine group? If the class was divided in a different manner the differences would disappear.
The purpose of the hypothesis test is to make a rational decision between the hypotheses of real effects and chance explanations. The scientist is never able to totally eliminate the chance explanation, but may decide that the difference between the two groups is so large that it makes the chance explanation unlikely. If this is the case, the decision would be made that the effects are real. A hypothesis test specifies how large the differences must be in order to make a decision that the effects are real.
At the conclusion of the experiment, then, one of two decisions will be made depending upon the size of the differences between the caffeine and no caffeine groups. The decision will either be that caffeine has an effect, making people more alert, or that chance factors (the composition of the group) could explain the result. The purpose of the hypothesis test is to eliminate false scientific conclusions as much as possible.
Hypothesis tests are procedures for making rational decisions about the reality of effects.
Most decisions require that an individual select a single alternative from a number of possible alternatives. The decision is made without knowing whether or not it is correct; that is, it is based on incomplete information. For example, a person either takes or does not take an umbrella to school based upon both the weather report and observation of outside conditions. If it is not currently raining, this decision must be made with incomplete information.
The concept of a decision by a rational man or woman is characterized by the use of a procedure that insures that both the likelihood and the potential costs and benefits of all events are incorporated into the decision-making process. The procedure must be stated in such a fashion that another individual, using the same information, would make the same decision.
One is reminded of a Star TrekK episode in which Captain Kirk is stranded on a planet without his communicator and is unable to get back to the Enterprise. Spock has assumed command and is being attacked by Klingons (who else?). Spock asks for and receives information about the location of the enemy, but is unable to act because he does not have complete information. Captain Kirk arrives at the last moment and saves the day because he can act on incomplete information.
This story goes against the concept of rational man. Spock, being a rational man, would not be immobilized by indecision. Instead, he would have selected the alternative which realized the greatest expected benefit given the information available. If complete information were required to make decisions, few decisions would be made by rational men and women. This is obviously not the case. The script writer misunderstood Spock and rational man.
When a change in one thing is associated with a change in another, we have an effect. The changes may be either quantitative or qualitative, with the hypothesis testing procedure selected based upon the type of change observed. For example, if changes in sugar intake in a diet are associated with activity level in children, we say an effect occurred. In another case, if the distribution of political party preference (Republicans, Democrats, or Independents) differs for sex (Male or Female), then an effect is present. Much of the behavioral science is directed toward discovering and understanding effects.
The effects discussed in the remainder of this text are measured using various statistics including: differences between means, a chi-Sqare statistic computed from a contingency tables, and correlation coefficients.
All hypothesis tests conform to similar principles and proceed with the same sequence of events.
In almost all cases, the researcher wants to find statistically significant results. Failing to find statistically significant results means that the research will probably never be published, because few journals will to publish results that could be due to haphazard or chance findings. If research is not published, it is generally not very useful.
In order to decide that there are real effects a model of the world is created in which there are no effects and the experiment is repeated an infinite number of times. The repetion is not real, but rather a "thought experiment", , or mathematical deduction. The sampling distribution is used to create the model of the world when there are no effects and the study is repeated an infinite number of times.
The results of the single real experiment or study are compared with the theoretical model of no effects. If, given the model, the results are unlikely, then the model and the hypothesis of no effects generating the model are rejected and the effects are accepted as real. If the results could be explained by the model, the model must be retained and no decision can be made about whether the effects were real or not.
Hypothesis testing is equivalent to the geometrical concept of hypothesis negation. That is, if one wants to prove that A (the hypothesis) is true, one first assumes that it isn't true. If it is shown that this assumption is logically impossible, then the original hypothesis is proven. In the case of hypothesis testing the hypothesis may never be proven; rather, it is decided that the model of no effects is unlikely enough that the opposite hypothesis, that of real effects, must be true.
An analogous situation exists with respect to hypothesis testing in statistics. In hypothesis testing one wants to show real effects of an experiment. By showing that the experimental results were unlikely, given that there were no effects, one may decide that the effects are, in fact, real. The hypothesis that there were no effects is called the null hypothesis. The symbol H0 is used to abbreviate the Null Hypothesis in statistics. Note that, unlike geometry, we cannot prove the effects are real, rather we may decide the effects are real.
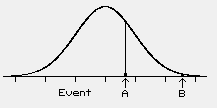
For example, suppose the probability model (distribution) in the following figure described the state of the world when there were no effects. In the case of Event A, the decision would be that the model could explain the results and the null hypothesis may true because Event A is fairly likely given that the model is true. On the other hand, if Event B occurred, the model would be rejected because Event B is unlikely, given the model.
The sampling distribution is a theoretical distribution of a sample statistic. It is used as a model of what would happen if
1. the null hypothesis were true (there really were no effects), and
2. the experiment were repeated an infinite number of times.
Because of its importance in hypothesis testing, the sampling distribution will be discussed in a separate chapter.
Probability theory essentially defines probabilities of simple events in algebraic terms and then presents rules for combining the probabilities of simple events into probabilities of complex events given that certain conditions are present (assumptions are met). As such, probability theory is a mathematical model of uncertainty. It can never be "true" in an absolute sense, but may be more or less useful; depending upon how closely it mirrors reality.
Probabilities in an abstract sense are relative frequencies based on infinite repetitions. The probability of heads when a coin is flipped is the number of heads divided by the number of tosses as the number of tosses approaches infinity. In a similar vein, the probability of rain tonight is the proportion of times it rains given that conditions are identical to the conditions right now and they happen an infinite number of times. In neither the case of the coin nor the weather is it possible to "know" the exact probability of the event. Because of this Kyburg and Smokler (1964), among others, have argued that all probabilities are subjective and reflect a "degree of belief" about a relative frequency rather than a relative frequency.
Flipping a coin a large number of times is more intuitive than the exact weather conditions repeating themselves over and over again. Maybe that is why most texts begin by discussing coin tosses and drawing cards in an idealized game. The essential fact remains that it is impossible to flip a coin an infinite number of times. The true probability of obtaining heads or tails must always remain unknown. In a similar vein, it is impossible to manufacture a die that will have an exact probability of 1/6 for each side, although if enough care is taken the long-term results may be "close enough" that the casino will make money. The difficulty of computing a truly random sequence of numbers to use in simulations of probability experiments is well-established (Peterson, 1998).
The conceptualization of probabilities as unlimited relative frequencies has certain implications for probabilities of events that fall on the extreme ends of the continuum, however. The relative frequency of an impossible event must always remain at zero, no matter how many times it is repeated. The probability of getting an "arm" when flipping a coin must be zero, because although "heads", "tails", or an "edge" are possibilities, a coin has no "arm". An "arm" will never appear no matter how many times I flip a coin; thus its probability is zero.
In a like manner the probability of a certain event is one. The probability of a compound event such as obtaining "heads", "tails", or an "edge" when flipping a coin is a certainty, as one of these three outcomes must occur. No matter how many times a coin is flipped, one of the outcomes of this compound event must occur each time. Because any number divided by itself is one, the probability of a certain event is one.
The two extremes of zero and one provide the upper and lower limits to the values of probabilities. All values between these extremes can never be known exactly.
In addition to defining the nature of probabilities, probability theory also describes rules about how probabilities can be combined to produce probabilities of compound and conditional events. A compound event is a combination of simple events joined with either "and" or "or". For example, the statement "Both the quarterback remains healthy and all the lineman all pass this semester" is a compound event, called a joint event, employing the word "and". In a similar vein, the statement "Either they all study very hard or they all get very lucky" is a compound event with the word "or". A conditional statement employs the term "given". For example, university football team will win the conference football championship next season given that the quarterback remains healthy and all the linemen pass this semester. The condition following the word "given" must be true before the condition before the "given" takes effect.
The probability of a compound event described by the word "and" is the product of the simple events if the simple events are independent. To be independent two events cannot possibly influence each other. For example, as long as one is willing to assume that the events of the quarterback remaining healthy and the linemen all passing are independent, then the probability of winning the conference football championship can be calculated by multiplying the probabilities of each of the separate events together. For example, if the probability of the quarterback remaining healthy is .6 and the probability of all the linemen passing this semester is .2, then the probability of winning the conference championship is .6 * .2 or .12. This relationship can be written in symbols as follows:
P ( A and B ) = P ( A ) * P ( B ) if A and B are independent events.
If the compound event can be described by two or more events joined by the word "or", then the probability of the compound event is the sum of the probabilities of the individual events minus the probability of the joint event. For example, the probability of all the linemen passing would be the sum of the probability of all studying very hard plus the probability of all being very lucky, minus the probability of all studying very hard and all being very lucky. For example, suppose that the probability of all studying very hard was .15, the probability of all being very lucky was .0588, and the probability of all studying very hard and all being very lucky was .0088. The probability of all passing would be .15 + .0588 - .0088 = .20. In general the relationship can be written as follows:
P ( A or B ) = P ( A ) + P ( B ) - P ( A and B )
A conditional probability is the probability of an event given another event is true. The probability that the quarterback will remain healthy given that he stretches properly at practice and before game time would be a conditional probability. By definition a conditional probability is the probability of the joint event divided by the probability of the conditional event. In the previous example, the probability that the quarterback will remain healthy given that he stretches properly at practice and before game time would be the probability of the quarterback both remaining healthy and stretching properly divided by the probability of stretching properly. Suppose the probability of stretching properly is .8 and the probability of both stretching properly and remaining healthy is .55. The conditional probability of remaining healthy given that he stretched properly would be .55 / . 8 = .6875. The "given" is written in probability theory as a vertical line (|), such that the preceding could be written as:
P ( A | B ) = P ( A and B ) / P ( B )
Conditional probabilities can be combined into a very useful formula called Bayes's Rule. This equation describes how to modify a probability given information in the form of conditional probabilities. The equation is presented in the following:
P ( A | B ) = ( P ( B | A ) * P ( A ) ) / ( P ( B | A ) * P ( A ) + P ( B | not A ) * P ( not A ) )
Where A and B are any events whose probabilities are not 0 and 1.
Suppose that an instructor randomly picks a student from a class where males outnumber females two to one. What is the probability that the selected student is a female? Given the ratio of males to females, this probability could be set to 1/3 or .333. This probability is called the prior probability and would be represented in the above equation as P(A). In a similar manner, the probability of the student being a male, P(not A), would be 2/3 or .667. Suppose additional information was provided about the selected student, that the shoe size of the person selected was 7.5. Often it is possible to compute the conditional probability of B given A or in this case, the probability of a size 7.5 given the person was a female. In a like manner, the probability of B given not A can often be calculated; in this case the probability of a size 7.5 given the person was a male. Suppose the former probability is .8 and the latter is .1. The likelihood of the person being a female given a shoe size of 7.5 can be calculated using Bayes's Rule as follows:
P ( A | B ) = ( P ( B | A ) * P ( A ) ) / ( P ( B | A ) * P ( A ) + P ( B | not A ) * P ( not A ) )
= (. 8 * .333 ) / ( .8 * .333 + .1 * .667 )
= .2664 / .3331 = .7998
The value of P ( A | B ) is called a posterior probability and in this case the probability of the student being a female given a shoe size of 7.5 is fairly high at .7998. The ability to recompute probabilities based on data is the foundation of a branch of statistics called Bayesian Statistics.
This set of rules barely scratches the surface when considering the possibilities of probability models. The interested reader is pointed to any number of more thorough treatments of the topic.
Including cost as a factor in the equation can extend the usefulness of probabilities as an aid in decision-making. This is the case in a branch of statistics called utility theory that includes a concept called utility in the equation. Utility is the gain or loss experienced by a player depending upon the outcome of the game and can be symbolized with a "U". Usually utility is expressed in monetary units, although there is no requirement that it must be. The symbol U(A) would be the utility of outcome A to the player of the game. A concept called expected utility would be the result of playing the game an infinite number of times. In its simplest form, expected utility is a sum of the products of probabilities and utilities:
Expected Utility = P ( A ) * U ( A ) + P ( not A ) * U ( not A )
Suppose someone was offered a chance to play a game with two dice. If the dice totaled to "6" or "8" the player would receive $70, otherwise he or she would pay $30. The utility to the player is plus $70 for A and minus $30 for not A. The probability of a "6" or "8" is 10/36 =.2778, while the probability of some other total is .7222. Should the player consider the game? Using expected utility analysis, the expected utility would be:
Expected Utility = ( .2778 * 70 ) + ( .7222 * (-30) ) = -2.22
Since the expected utility is less than 0, indicating a loss over the long run, expected utility theory would argue against playing play the game. Again this illustration just barely scratches the surface of a very complex and interesting area of study and the reader is directed to other sources for further study. In particular, the area of game theory holds a great deal of promise.
Your should be aware that the preceding analysis of whether on not to play a given game based on expected utility assumes that the dice are "fair", that is, each face is equally likely. To the extent the fairness assumption is incorrect, for example using weighted dice, then the theoretical analysis will also be incorrect. Going back to the original definition of probabilities, that of a relative frequency given an infinite number of possibilities, it is never possible to "know" the probability of any event exactly.
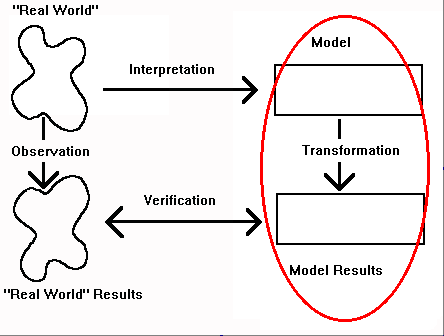
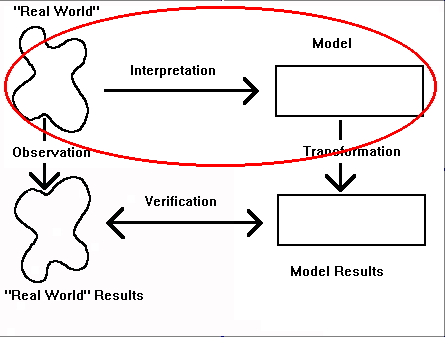
Does this mean that all the preceding is useless? Absolutely not! It does mean, however, that probability theory and probability models must be viewed within the larger framework of model-building in science. The "laws" of probability are a formal language model of the world that, like algebra and numbers, exist as symbols and relationships between symbols. They have no meaning in and of themselves and belong in the circled portion of the model-building paradigm.
As with numbers and algebraic operators, the symbols within the language must be given meaning before the models become useful. In this case "interpretation" implies that numbers are assigned to probabilities based on rules. The circled part of the following figure illustrates the portion of the model-building process that now becomes critical.
There are a number of different ways to estimate probabilities. Each has advantages and disadvantages and some have proven more useful than others. Just because a number can be assigned to a given probability symbol, however, does not mean that the number is the "true" probability.
When there is no reason to believe that any outcome is more or less likely than any other outcome, then the solution is to assign all outcomes an equal probability. For example, since there is no reason to believe that heads is more likely than a tails a value of .5 is assigned to each when a coin is flipped. In a similar manner, if there is no reason to believe that one card is more likely to be picked than any other, then a probability of 1/52 or .0192 is assigned to every card in a standard deck.
Note that this system does not work when there is reason to believe that one outcome is more likely than another. For example, setting a probability of .5 that it will either be snowing outside in an hour is not reasonable. There are two alternatives, it will either be snowing or it won't, but equal probabilities are not tenable because it is sunny and 60 degrees outside my office right now and I have reason to believe that it will not be snowing in an hour.
The relative frequency of an event in the past can be used as an estimate of its probability. For example, the probability of a student succeeding in a given graduate program could be calculated by dividing the number of students actually finishing the program by the number of students admitted in the past. Establishing probabilities in this fashion assumes that conditions in the past will continue into the future, generally a fairly safe bet. The greater the number of observations, the more stable the estimate based on relative frequency. For example, the probability of a heads for a given coin could be calculated by dividing the number of heads by the number of tosses. An estimate based on 10,000 tosses would be much better than one based on 10 tosses.
The probability of snow outside in a hour could be calculated by dividing the number of times in the past that it has snowed when the temperature an hour before was 60 degrees by the number of times it has been 60 degrees. Since I don't have accurate records of such events, I would have to rely on memory to estimate the relative frequency. Since memory seems to work better for outstanding events, I am more likely to remember the few times it did snow in contrast to the many times it did not.
The problems with using relative frequency were discussed in some detail in Chapter 5, "Frequency Distributions." If an estimate of the probability of females who wear size 7.5 shoes is needed, one could use the proportion of women wearing a size 7.5 in a sample of women. The problem is that unless a very large sample of women's shoe sizes is taken, the relative frequency of any one shoe size is unstable and inaccurate. A solution to this dilemma is to construct a theoretical model of women's shoe sizes and then use the area under the theoretical model between values of 7.25 and 7.75 as an estimate of the probability of a size 7.5 shoe size. This method of establishing probabilities has the advantage of requiring a much smaller sample to estimate relatively stable probabilities. It has the disadvantage that probability estimation is several steps removed from the relative frequency, requiring both the selection of the model and the estimation of the parameters of the model. Fortunately, selecting the correct model and estimating parameters of the models is a well-understood and thoroughly studied topic in statistics.
Area under theoretical models of distributions is the method that classical hypothesis testing employs to estimate probabilities. A major part of an intermediate course in mathematical statistics is the theoretical justification of the models that are used in hypothesis testing.
A controversial method of estimating probabilities is to simply ask people to state their degree of belief as a number between zero and one and then treat that number as a probability. A slightly more sophisticated method is to ask the odds the person would be willing to take in order to place a bet. Probabilities obtained in this manner are called subjective probabilities. If someone was asked "Give me a number between zero and one, where zero is impossible and one is certain, to describe the likelihood of Jane Student finishing the graduate program." that number would be a subjective probability.
Subjective probabilities have the greatest advantage in that they are intuitive and easy to obtain. People use subjective probabilities all the time to make decisions. For example, my decision about what to wear when I leave the house in the morning is partially based on what I think the weather will be like an hour from now. A decision on whether or not to take an umbrella is based partly on the subjective probability of rain. A decision to invest in a particular company in the stock market is partly based on the subjective probability that the company will increase in value in the future.
The greatest disadvantage of subjective probabilities is that people are notoriously bad at estimating the likelihood of events, especially rare or unlikely events. Memory is selective. Human memory is poorly structured to answer queries such as estimating the relative frequency of snow an hour after the temperature was 60 degrees Fahrenheit and likely to be influenced by significant, but rare, events. If asked to give a subjective probability of snow in an hour, the resulting probability estimate would be a compound probability resulting from a large number of conditional probabilities, such as the latest weather report, the time of year, the current temperature, and intuitive feelings.
Subjective probability estimates are influenced by emotion. In assessing the likelihood of your favorite baseball team winning the pennant, feelings are likely to intervene and make the estimate larger that reality would suggest. Bookmakers (bookies) everywhere bank on such human behavior. In a similar manner, people are likely to assess the likelihood of experimental methods to cure currently incurable diseases as much higher than they actually are, especially when they have an incurable disease. The foundation of lotteries is an overestimate of the probability of winning. Almost every winner in a casino is celebrated by lights flashing and bells ringing, causing patrons to maintain a general overestimate of the probability of winning.
People have a difficult time assessing risk and responding appropriately, especially when the probabilities of the events are low. In the late 1980's people were canceling overseas travel because of threats of terrorist attacks. Paulos (1988) estimates that the likelihood of being killed by terrorists in any given year is one in 1,600,000 while the chances of dying in a car crash in the same time frame is one in only 5,300. Yet people still refuse to use seat belts.
When people are asked to estimate the probability of some event, the event occurs, and then the same people are asked what their original probabilities were, they almost inevitably inflate them in the direction of the event. For example, suppose people were asked to give the probability that a particular candidate would win an election, the candidate won, and then the same people were asked to repeat the probability that they originally presented. In almost all cases, the probability would be higher than the original probability. This well-established phenomenon is called hindsight bias (Winman, Juslin, and Bjorkman, 1998)
Since most subjective probability estimates are compound probabilities, humans have also have a difficult time combining simple probabilities into compound probabilities. Some of the difficulty has to do with a lack of understanding about independence and mutual exclusivity necessary to multiply and add probabilities. If a couple has three children, all boys, the probability of the next child being a boy is approximately .5, even though the probability of having four boys is .54 or .0625. The correct probability is a conditional probability of having a boy given that they already had three boys.
Another difficulty with probabilities has to do with a misunderstanding about conditional probability. When subjects were asked to rank potential occupations of a person described by a former neighbor as "very shy and withdrawn, invariably helpful, but with little interest in people, or in the world of reality. A meek and tidy soul, he has a need for order and structure, and a passion for detail.", Tversky and Kahneman (1974, p. 380) found that they inevitably categorize him as a librarian rather than a farmer. People fail to take into account that the base rate or prior probability of being a farmer is much higher than being a librarian.
Using this and other illustrations of systematic and predictable errors made by humans is assessing probabilities, Tversky and Kahneman (1974) argue that reliance on subjective probabilities to assign values to symbols used within probability theory will inevitably lead to logical contradictions.
The casinos in Las Vegas and around the world are testaments that probability models work as advertised. Insurance companies seldom go broke. There is no question that probability models work if care is used in their construction and the user has the ability to participate for the long run. These models are so useful that Peter Bernstein (1996) has claimed (p. 1) "The revolutionary idea that defines the boundary between modern times and the past is the mastery of risk: the notion that the future more than a whim of the gods and that men and women are not passive before nature."
In hypothesis testing, probability models are used to control the proportion of times a researcher claims to have found effects when in fact the results were due to chance or haphazard circumstances. Because the science as a whole is able to participate in the long run, these models have been successfully applied with the result that only a small proportion of published research is the result of chance, coincidence, or haphazard events.
Most of the decisions that are made in real life are made without the ability to view the results in the long run. An undergraduate student decides to apply to a given graduate school based upon an assessment of the probability of a favorable outcome and the benefits of attending that particular school. There is generally no opportunity to apply to the same program over and over again and observe the results. Probability models have limited value in these situations because of the difficulties in estimating probabilities with any kind of accuracy.
Personally, I use expected utility theory in justifying not playing the lottery or gambling in casinos. If the expected value is less than zero, I don't play. That doesn't explain why I carry insurance on my house and my health, other than the bank requires it for a mortgage and the university provides it as part of my benefits.
It has been fairly well-established that probability and utility theory and not accurate normative models of how people actually make decisions. Harvey (1998) argues that people use a variety of heuristics, or rules of thumb, to make decisions about the world. An awareness and use of probability and utility theory have the potential benefit of making the people much better decision-makers and are worthy of further study.
Hypothesis tests are procedures for making rational decisions about the reality of effects. All hypothesis tests proceed by measuring the size of an effect, or relationship between two variables, by computing a statistic. A theoretical probability model or distribution of what that statistic would look like given there were no effects is created using the sampling distribution. The statistic that measures the size of the effect is compared to the model of no effects. If the probability of the obtained value of the statistic is unlikely given the model, the model of no effects is rejected and the alternative hypothesis that there are real effects is accepted. If the model could explain the results, the model and the hypothesis that there are no effects is retained, as is the alternative hypothesis that there are real effects.